
The twilight of the chatbots
How work changes along the exponential

If you feel like things are accelerating in AI, you are probably right. Better AI models from the leading American AI labs have been releasing more quickly than ever (though government interventions have stopped access to two of the most powerful models, Claude Fable and GPT-5.6).
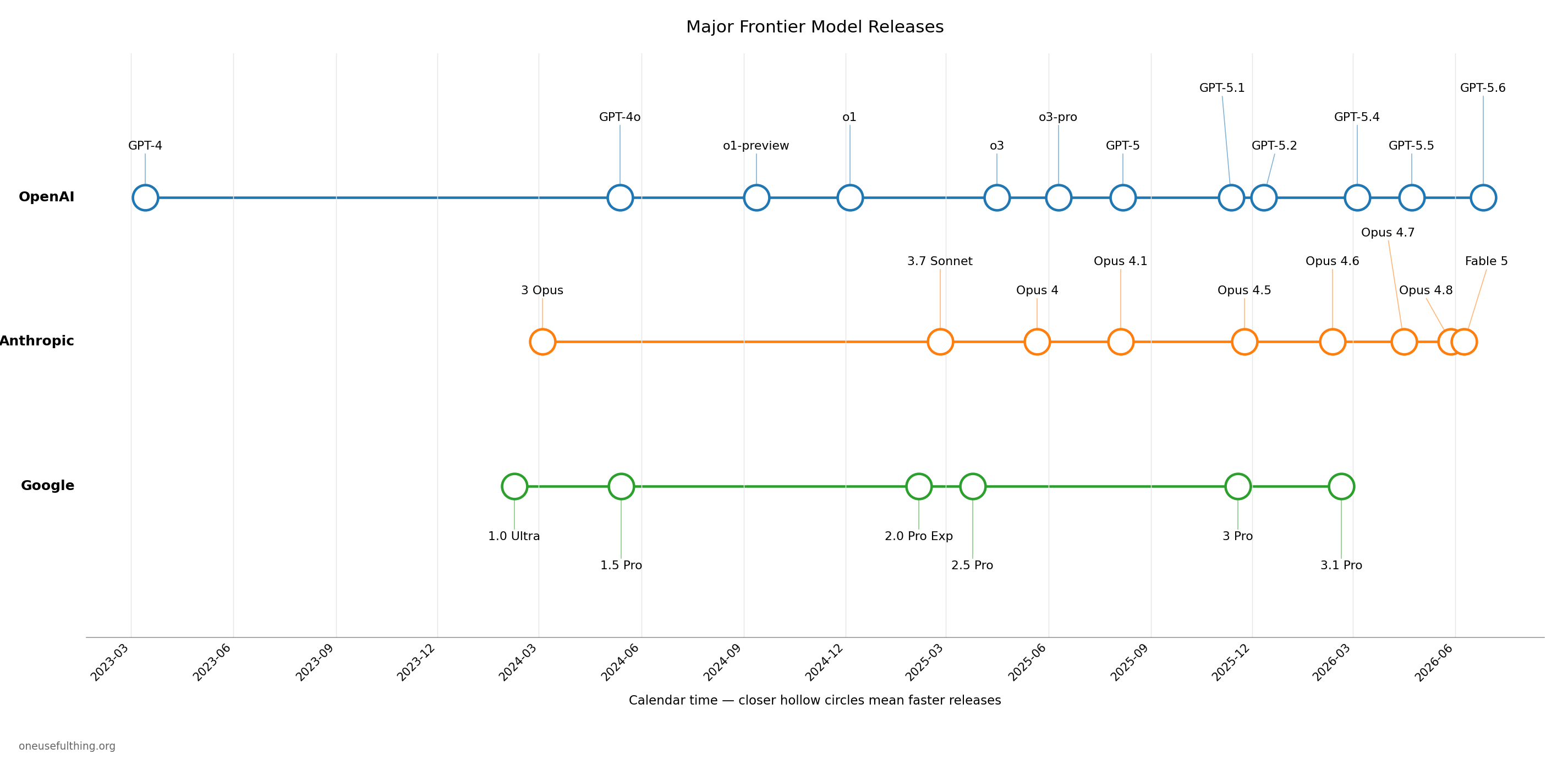
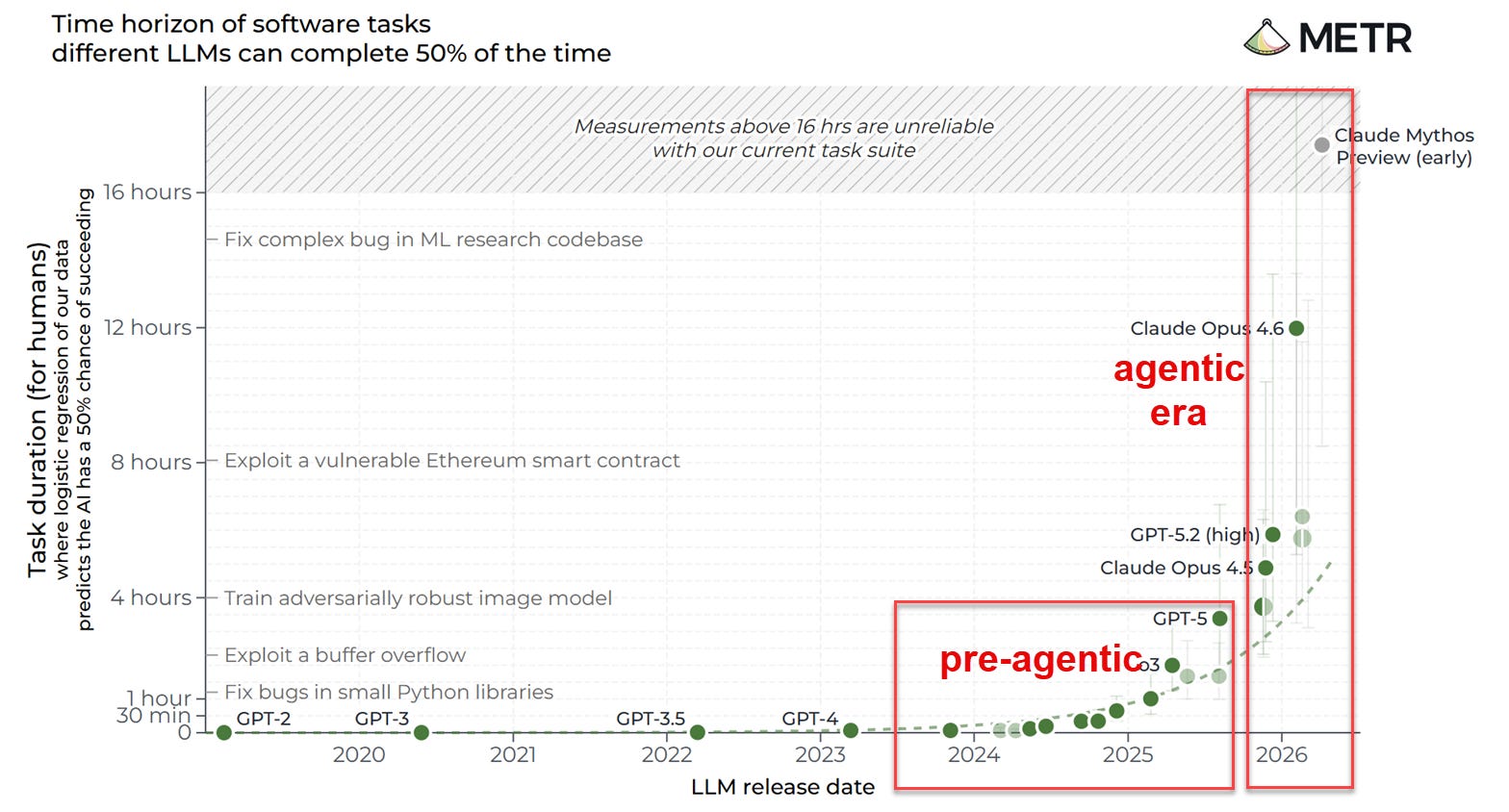
But it isn't just release timing. The evidence points to accelerating capability gains as well (though the frontier stays jagged, and AIs remain weak in many places). This is especially obvious when we look at the ability of AIs to do real work. There are a few good assessments that try to measure how much human work AIs can do. Two of the most famous, from METR and the UK’s official government AI Security Institute, estimate the amount of human programmer hours’ worth of effort the AI can do with a single prompt. GDPval compares human experts in many fields to AI performance using professional judges. They are all increasing at a better than exponential rate.

Another organization doing similar experiments, Epoch, recently found Opus 4.7, working on its own for 14 hours, was able to build a software package that would take 2-17 weeks of human engineering work (it cost $251 in tokens). Again, AI systems cannot pass every test, nor are they always cheap to run, but they are definitely improving at a very rapid rate. In my own experiments, I found Fable was able to work autonomously for 9 hours to execute on very complex software projects that would have taken a team well over a week to do.

So far, I have focused on the frontier models, those with the highest “intelligence.” They are made by three American companies — Anthropic, OpenAI, and Google (though it has been a while since Google has released a new model). But there is a second set of AI models that typically lag 6-12 months behind the frontier, all of which are from China. These are open weights models, which means that anyone can use or modify them after release (as opposed to the frontier models which are proprietary). That makes them quite cheap to operate. They, too, are climbing up an exponential improvement curve, though lagging the American models. You can see this in my graph of AI performance in a test called AA-Briefcase, which simulates a complex multi-week consulting engagement where AI has to do many kinds of analysis. The open-weights models are on their own exponential curve, behind closed US models
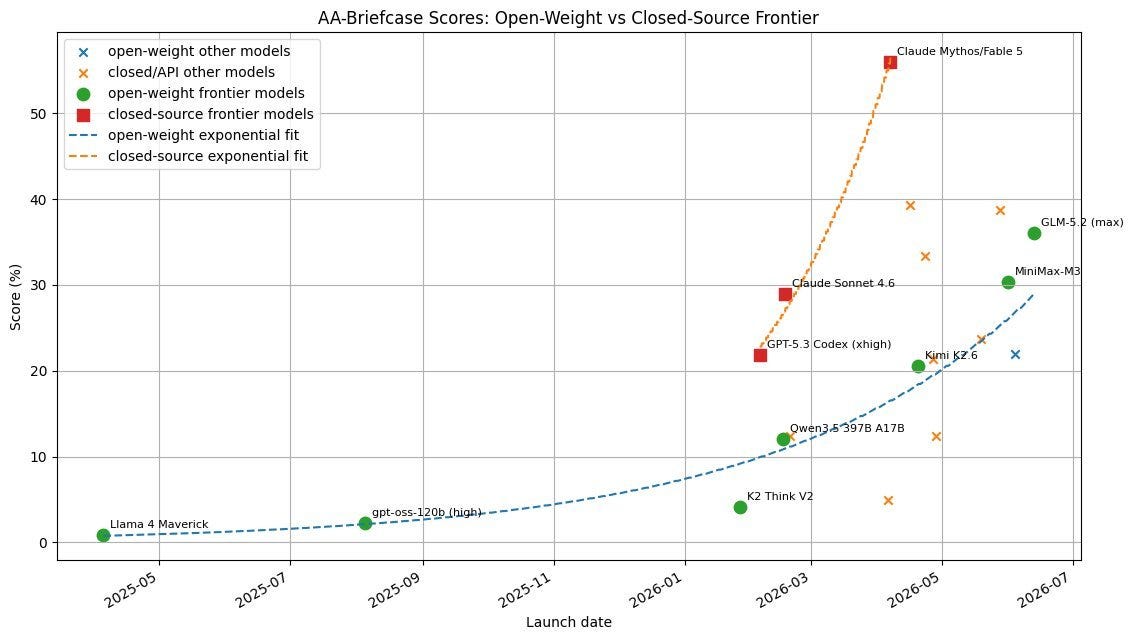
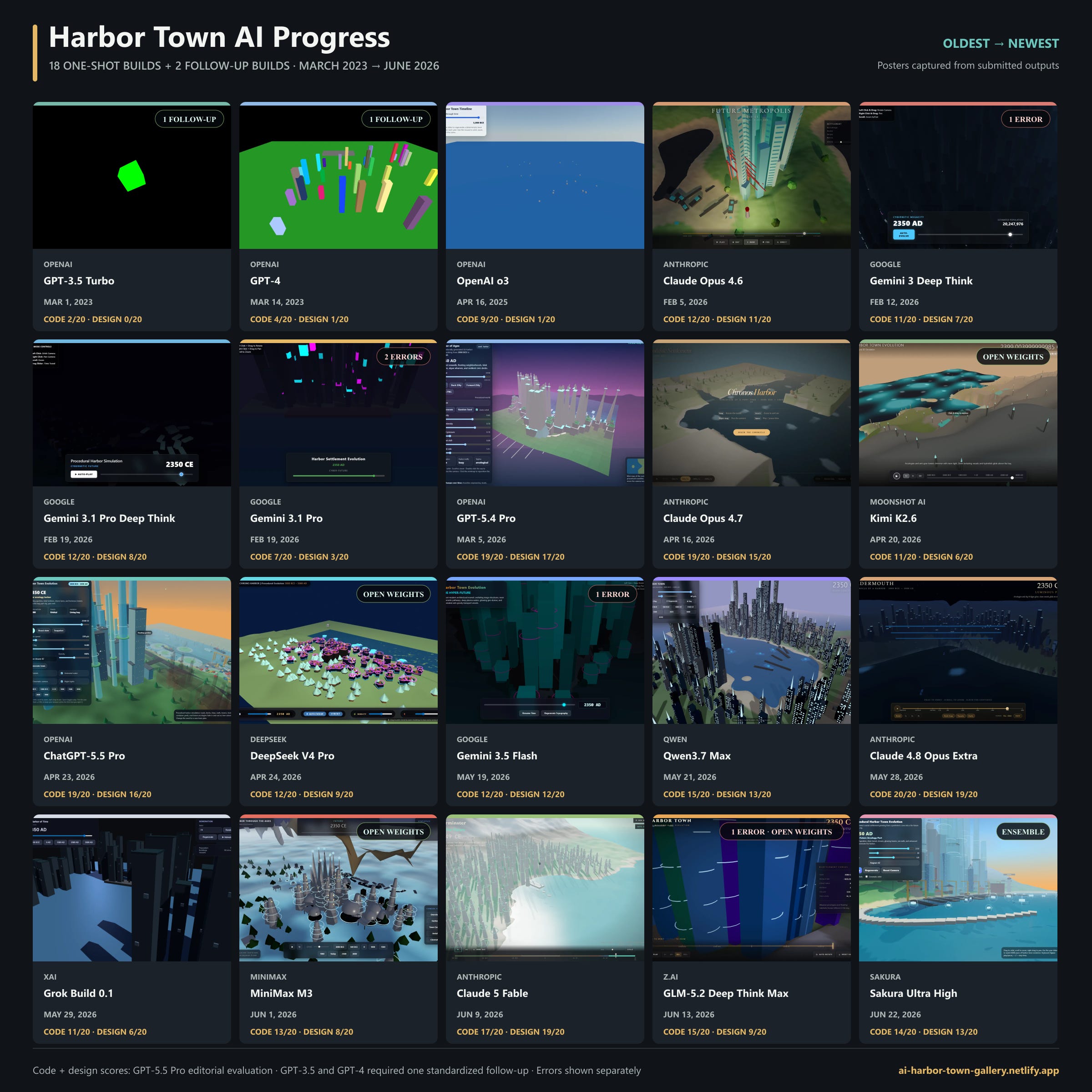
But abstract graphs only get you so far, and they can hide how jagged the frontier is (and also the fact that the open weights models, while very impressive, do not always perform as well as their benchmarks would indicate). To get real insight, you need to try using AI for different use cases and rigorously assess how good they are in the areas that matter to you. As a fun example, I created a test where AIs have to build an interactive simulation of a harbor evolving over time. You can play with all the result here. I think it gives an interesting perspective on how much models can differ from each other in areas like design, stylistic approach, and even judgement. As systems do ever longer tasks, these hard-to-benchmark factors become more important.
The way we use AI is changing
As AIs can do longer and longer tasks, the way people are using AI is changing. Until recently, the dominant way to use AI was as a co-intelligence. You would ask the AI to do something, check the results, and then ask for it to do the next step of your job. By careful prompting and human attention, you could guide AIs to do complex and long-term tasks.
This approach to using AI is still common and useful, but, increasingly, it is not the way AI is being used for valuable work. Long-running, smart, and self-correcting AI systems do not need constant human intervention, and they require a different way of working (this is also the subject of my upcoming book, Co-Existence, which you might want to pre-order here). And, as opposed to chatbots, agents come with extra machinery: harnesses that give the AI access to tools and an environment to act in, and apps built for agents like Claude Code or OpenAI's Codex. As a result, the already increasing ability of AI models can be improved still further by a good harness or app.
So work is increasingly about assigning work to agents, rather than working together with chatbots. A joint study by OpenAI and academic economists shows how quickly this is happening inside their own organization. Critically, it isn’t just coders who are using agents. Legal, HR, and other non-tech functions have adopted agents at nearly the same rate. OpenAI may be a sort of canary in the coal mine for what will happen elsewhere in work.
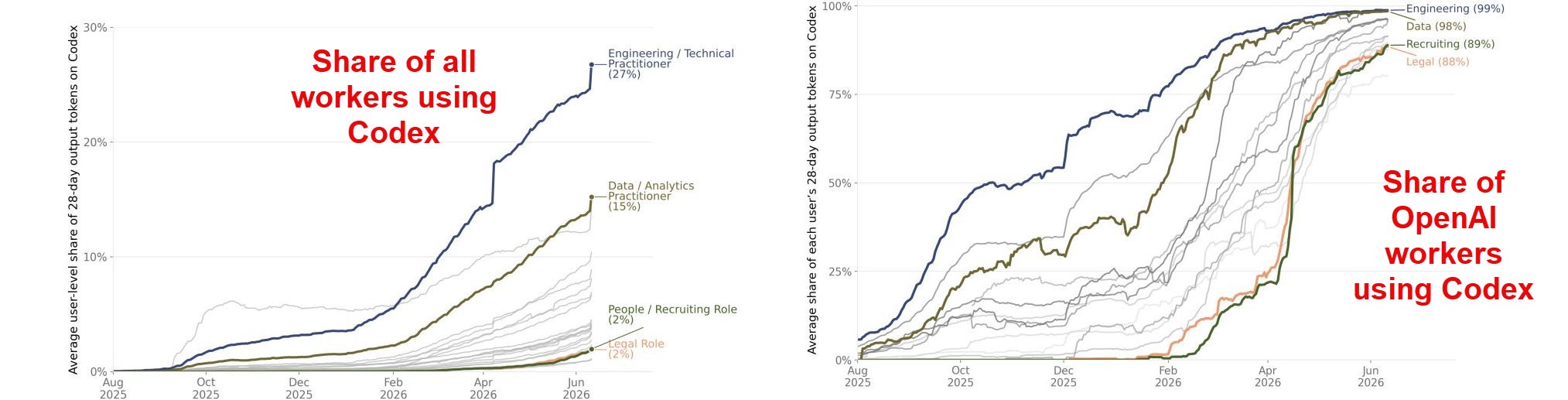
Increasingly, work at OpenAI looks like managing AI. A quarter of OpenAI workers have at least four agents running at one time every week. And, as coding is done by AIs in specialized harnesses and apps, other roles start to become coders of a sort. And they are good at it. A separate study of Claude Code users found that software engineers had a similar success rate to other professions when actually using Claude code on coding tasks.

What actually mattered was not the profession of the user, but their expertise. The more domain experience someone had, the more successful they were in using Claude Code in that domain. And, even more interestingly, the more useful output they got from Claude from each prompt.
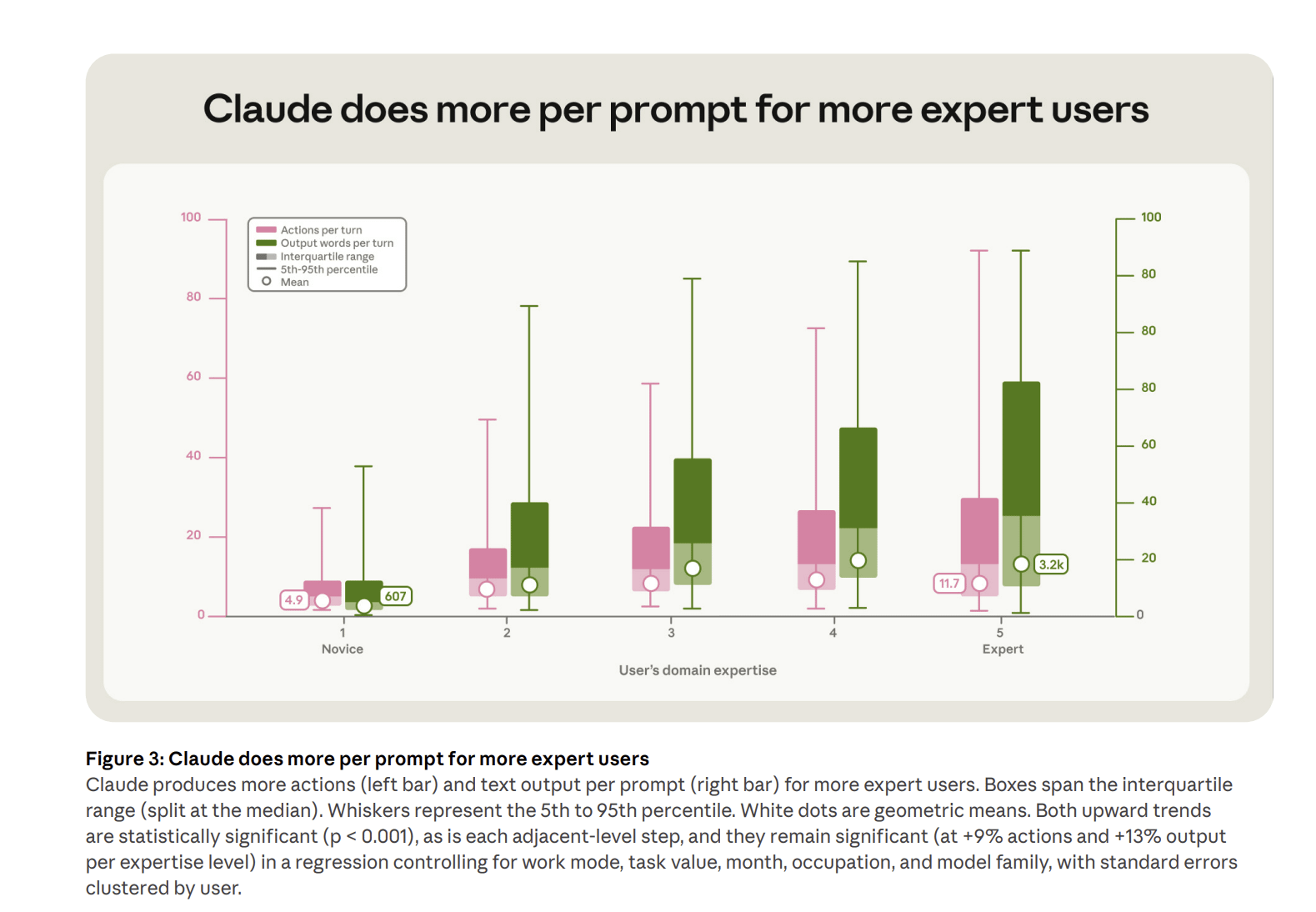
We are moving from a world where non-experts use chatbots to fill in gaps to one in which experts use agents to get work done. And the best way to use agents is to think of yourself as a manager.
A moment in time
Being on an exponential means each change over a fixed window is larger than the one before it. If your organization wrote an AI plan any time before the winter of 2025, it described a system that could do a couple of hours of work with a fairly high error rate. A few months later, you can get sixteen hours or more of work from a single prompt. This is why AI keeps feeling like it is making leaps, even though it is a curve on a graph, we keep experiencing a steady doubling of capability as a series of shocks. We are very bad at feeling exponentials from the inside, and we are currently inside one.
I think this also explains the turbulence around AI better than the usual stories about hype. AI is not capable of being a real cybersecurity threat until suddenly it is, causing sudden and improvised policy changes at the highest level of government. Markets discount whether AI might threaten to undermine a business model until suddenly it can, leading to massive swings in stocks. These lurches these get read as signs of an immature field that will eventually settle into something stable. I don’t think it is going to settle anytime soon. The instability is what happens when institutions that move at the speed of people (or worse, committees) try to track a capability curve that is very much not human in nature. And as long as we are on some sort of exponential, and for as long as it lasts, the gap only widens.

It would be interesting to see a chart showing token costs when an agent runs for days comparing the open vs. frontier models. It seems that if the agentic capability is growing this fast, the costs could get out of control quickly. This in turn seems like it would be a big push toward open and undermine frontier unless it's a critical or unique project. Am i missing something?
You do not consider Gemma 4 an open weight model released by a non-Chinese company, specifically Google? Or is April too far in the past to count? ... maybe it is, Anthropic released three since then.
My own expectation is that the frontier becomes too expensive for most jobs and we end up running local models, or open models in our own cloud, for most use cases.