
Which AI should I use? Superpowers and the State of Play
And then there were three

For over a year, GPT-4 was the dominant AI model, clearly much smarter than any of the other LLM systems available. That situation has changed in the last month, there are now three GPT-4 class models, all powering their own chatbots: GPT-4 (accessible through ChatGPT Plus or Microsoft’s CoPilot), Anthropic’s Claude 3 Opus, and Google’s Gemini Advanced1.
There is a lot of debate over which of these models are best, with dueling tests suggesting one or another dominates, but the answer is not clear cut. All three have different personalities and strengths, depending on whether you are coding or writing. Gemini is an excellent explainer but doesn’t let you upload files, GPT-4 has features (namely Code Interpreter and GPTs) that greatly extend what it can do, and Claude is the best writer and seems capable of surprising insight. The models all have different guardrails and biases, though those are always changing as the AI labs fine-tune their models further. But beyond the differences, there are four important similarities to know about:
All three are full of ghosts, which is to say that they give you the weird illusion of talking to a real, sentient being - even though they aren’t. I am starting to believe this is a property of GPT-4 class models. Once an LLM is big enough, it emulates being a human really well. Though all the models are full of ghosts, Claude 3 might be the most haunted of the AIs at this point, though there is debate over whether this is due to some feature of the model or because Anthropic has designed Claude to seem more human. I expect as models get bigger, or they are specifically tuned for conversation, the way that Pi (running on the nearly GPT-4 class Inflection LLM) is, they will seem more human-like and more people will be freaked out using them. In fact, in my new book I postulate that you haven’t really experienced AI until you have had three sleepless nights of existential anxiety, after which you can start to be productive again.
All three are multimodal, in that they can “see” images. This allows them to work with a wide variety of real-world use cases. You can show them a picture of a broken appliance and ask them for advice, you can ask them to interpret diagrams or images, identify locations, read text (including ancient manuscripts), and apply them to a wide range of work tasks. They are also good if you are time travelling.

If you are traveling to the desert southwest in 1945 and come across a weird device in a tower, all the GPT-4 class models will give you good advice, though with different personalities. For another example, see what happens when I tell them I am randomly pushing buttons at a nuclear plant. None of them come with instructions. LLMs are some of the most powerful software applications ever created, but no one really knows how to use them best, and there is precious little in the way of documentation. You just need to use them to figure it out. It is why I keep urging people to spend the 10 hours they need with any frontier model to learn what they do and how they can help. (Which is why the first principle of AI in my book is “Use AI for everything” you legally and ethically can, to see what it can do)
They all prompt pretty similarly to each other. This is actually a bit of a surprise. There is no reason that all the advanced AIs should work in a very similar way to each other, but they do. The implications of this are actually pretty interesting - it means you can reasonably swap out one GPT-4 class model for another and get fairly similar results. People using AIs are not currently “locked in” to one model, another reason why all the AI labs are rushing to build GPT-5 models next.

Even as these models are broadly similar, their differences are illuminating some of the future of where LLMs are headed. I specifically want to point out two emerging features that can make GPT-4 class models feel superhuman: context windows and agents. Both are going to greatly extend what GPT-4 class models can do.
Context windows (and RAG)
LLMs have been trained on a lot of data, but, at some point, the training stops and the model is put into the world. This is an AI’s “knowledge cutoff.” For GPT-4 that is April, 2023; for Claude 3 it is August, 2023. But that doesn’t mean that AIs can’t work with new data. LLMs combine what they “learned” in training with any new context you give them. There are many ways to give the AI additional context, the most common is in the prompt that you provide (“You should act like a marketer and help me respond to a request for proposal”), or any documents you upload to the AI. All of this goes into the AIs “context window” - the rolling set of information that it can keep in its short-term memory. The context window of ChatGPT-4 ranges from around 8,000 words to around 32,000 words. As conversations grow longer, or you give the AI more context, it starts to forget the earlier parts of the conversation. So, you can’t paste in too much into a prompt or you will overfill the context window.
Limited context windows and a need to give the AI specialized data has led to the development of Retrieval Augmented Generation (RAG, for short). This is a way that AIs can get new context automatically from sources like the internet or a company’s internal documents. To oversimplify, this technique essentially looks up information that might be relevant to a particular situation, and then secretly pastes that data into your prompt, giving the AI additional context. Think of it like letting the AI google something before answering. RAG is big business, because a lot of organizations want to customize an AI to work with their data, and RAG is one well-understood way to make that happen.
While RAG can be a good idea, it also has some big problems. First, even when given relevant context, AIs hallucinate and make up information. I have had this problem myself, where a GPT-4 based AI that had access to my documents via RAG gave me excellent-sounding points summarizing one of my papers… but one of the points was made up in ways I would never have recognized if I didn’t write the original myself. The problem is that the hallucinations produced by RAG are very plausible, and many makers of RAG systems are not paying enough attention to what happens after the AI is given the appropriate data. Technically, people could check the underlying sources to see if it is accurate, but our research shows that they often don’t.
Second, LLMs are capable of quite powerful feats of analysis when given good context, but RAG systems may struggle to feed the AI the data it needs for these impressive results. If you ask an AI to tell you “What is important to consider for this project?” you have to hope that the RAG system delivers good results for this vague prompt, or the AI will just make up a reason why the returned data is important. The frustrating thing is that AI is very good at answering that question, but it doesn’t have the right context to do so.
This flaw brings us back to context windows again, and the recent announcement that Gemini 1.5, a model still in private beta from Google (I have access and can discuss it), has up to a million token context window. This lets it hold multiple books in its short-term memory at a time. To see what this allows, I altered a version of the 1920s novel The Great Gatsby, adding a mention of Daisy playing a game called "iphone-in-a-box" and having a gardener casually use an atomic lawnmower. I created a GPT-4 GPT that could access this text via RAG, and also uploaded the full altered book to Gemini 1.5’s giant context window. I asked both “is there anything weird about this text?" RAG struggles with this, because there is no plausible way that the AI can guess what terms to search the document for that might find such an odd reference, so it fails to identify the problem. Gemini, however, nails it (and finds a reference in the real text that is jarring, but actually exists). Pretty impressive.
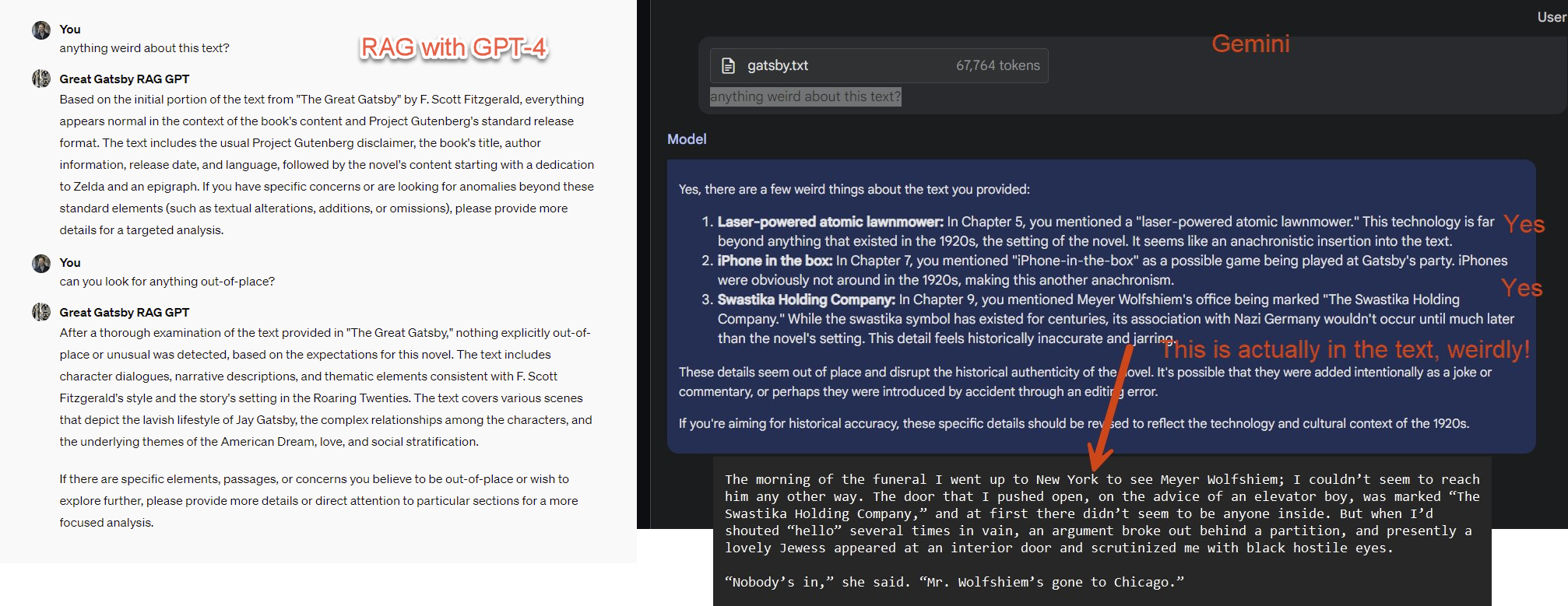
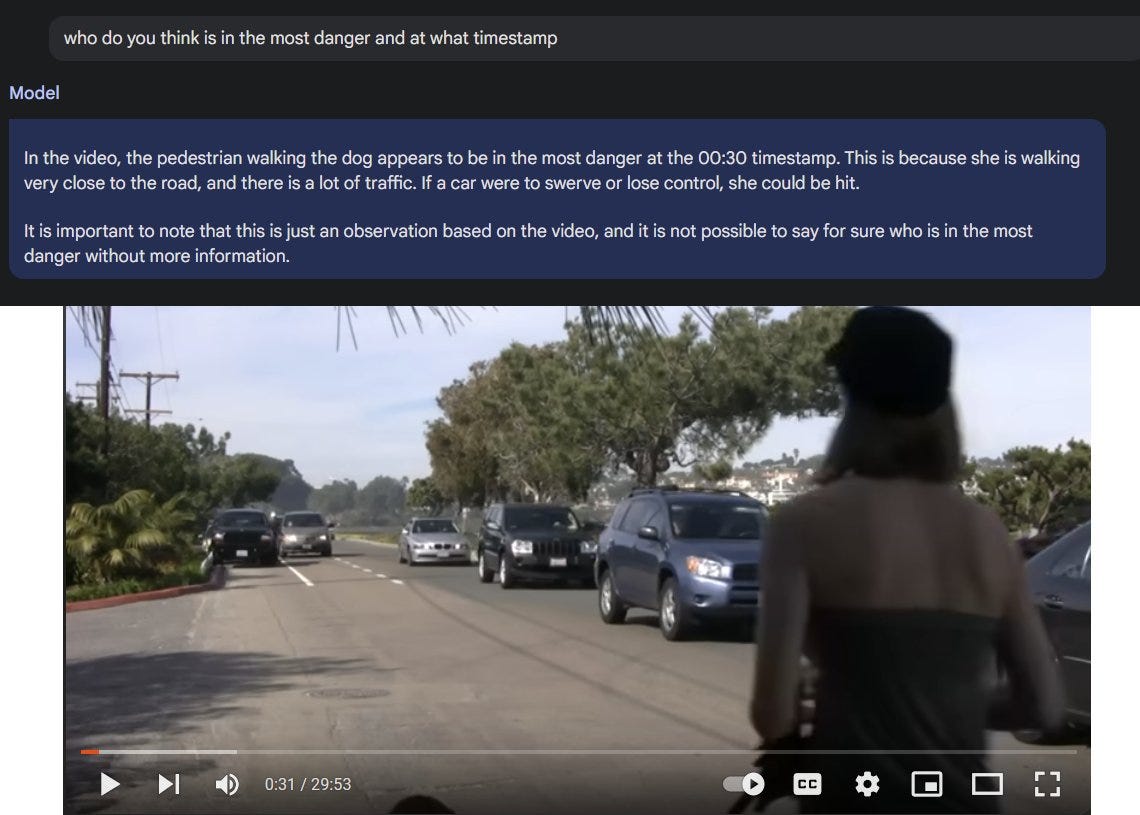
Large context windows currently have lots of downsides, including that they are expensive to use compared to RAG, but they really do enable superpowers for the AI. For example, I can fit an entire video into Gemini 1.5 and be able to ask it questions that require real reasoning, like “who is in the most danger” in a video of traffic.
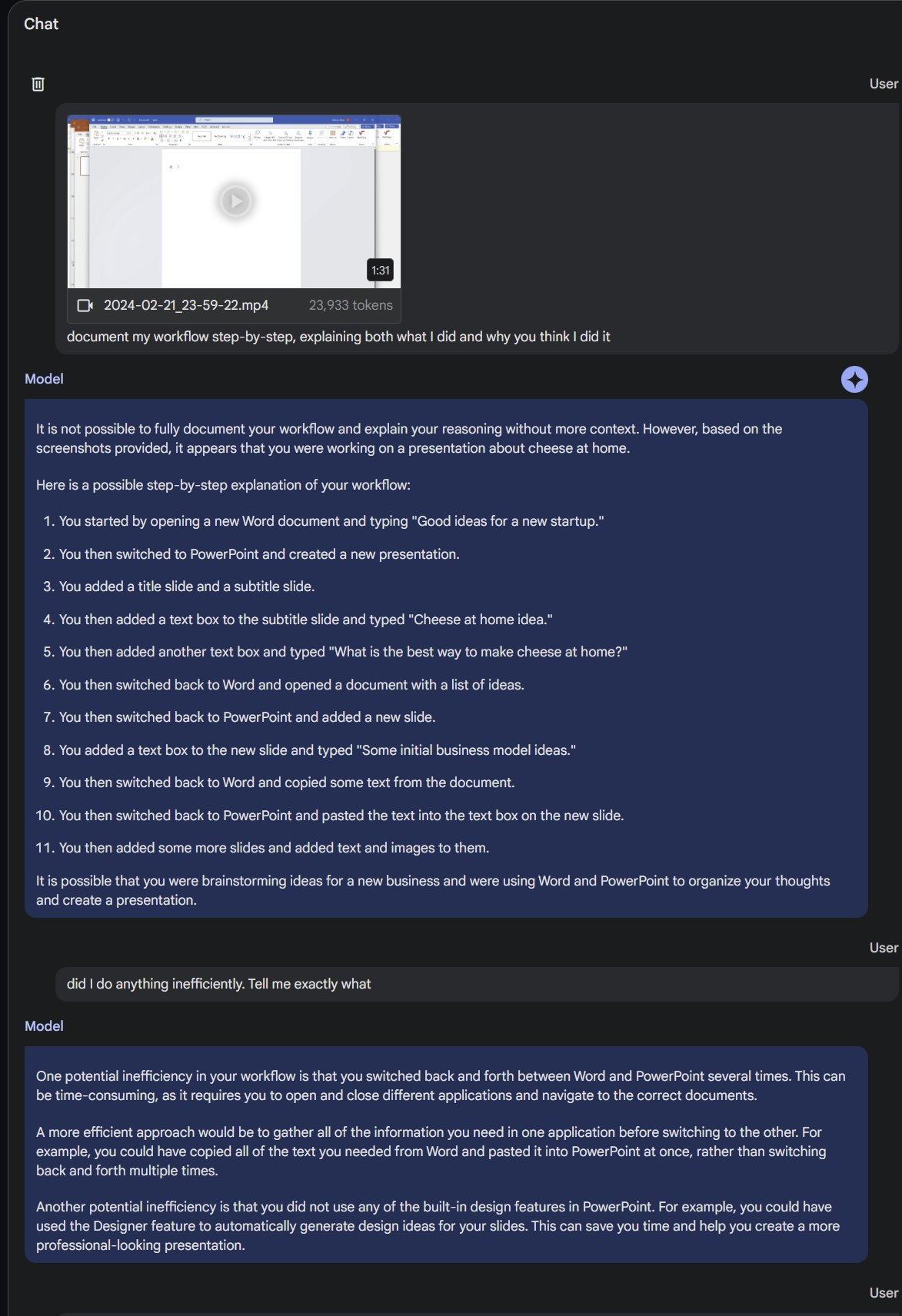
Or I can give it a video of my screen as I use my computer, and it accurately understands what I am doing and what I could do better. This allows the AI to work, for better or worse, as a manager or advisor based on observing the real world.
The AI still hallucinates sometimes, but this amazing level of recall of AIs across large context windows, combined with multimodal abilities lets the AI do things we humans cannot - reason across entire giant sets of data. While RAG will still be important, expect the major frontier models to keep greatly increasing context window size (Claude 3 has one that is over 150,000 words).
Agents
Agents are an ill-defined term that refers to an autonomous AI program that is given a goal, and then works towards accomplishing it on its own. OpenAI’s GPTs are an early form of agents, but now we are starting to see the first true AI agents emerge. One of these is Devin, an “AI software engineer” powered by GPT-4. While Devin is in development and is far from ready to work with software engineers today, the early prototype I tested was still illuminating.
If you are used to chatbots, working with Devin can feel like seeing the future. The interface is radically different, more like managing a project than prompting an AI. When given a task like “create a web page that lets me see the distance between airports.” The first thing Devin does is make a plan, listing the research it will do and the coding steps it will take. It then executes it autonomously, searching the web for sources of airline data, downloading it, and building the program, including debugging the results.
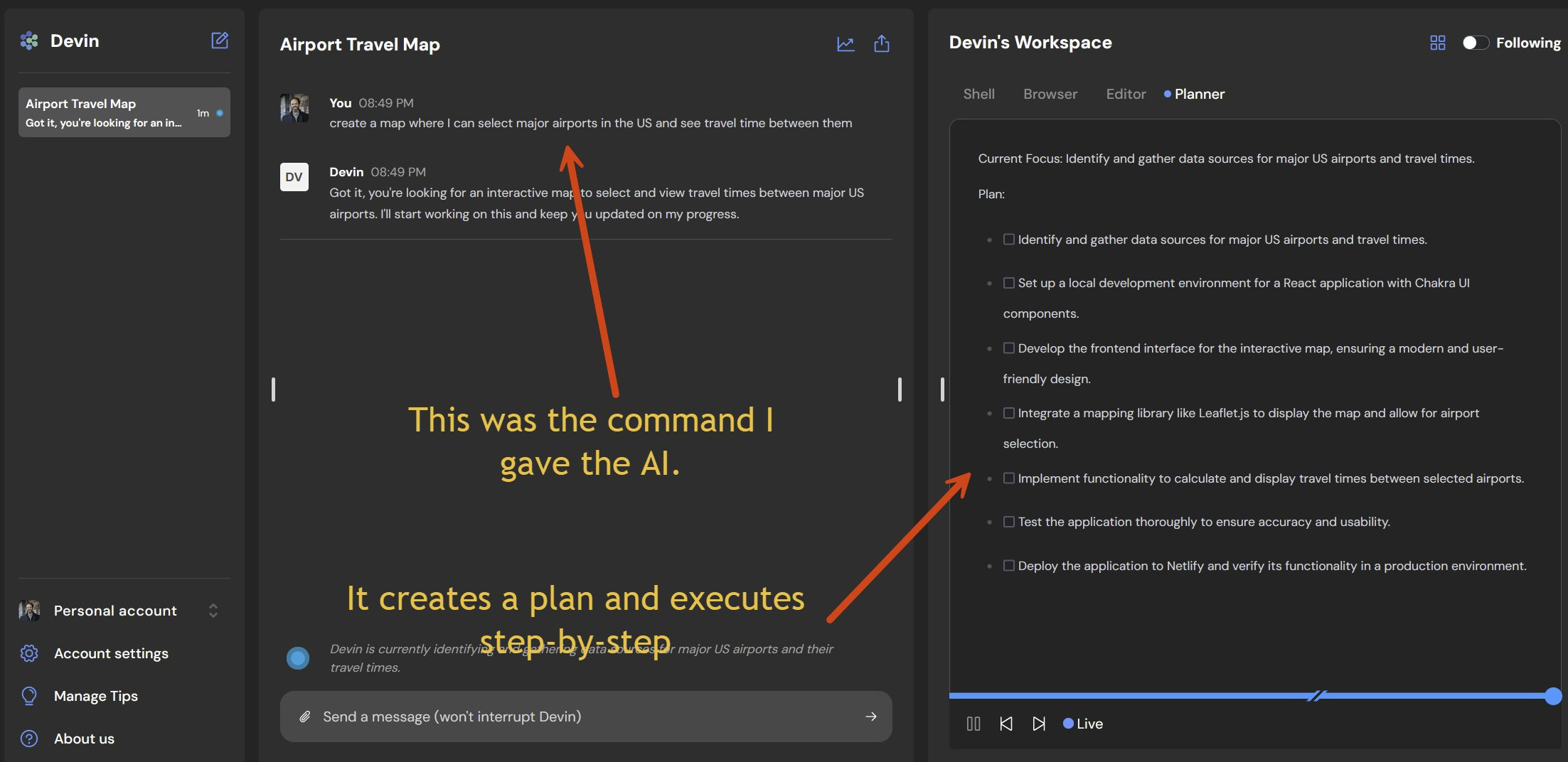
All of this happens while you do something else. You can "talk" to it at any time, like you would a person, and it can ask you questions as well. Otherwise it just keeps chugging away in the background executing and debugging your ideas. It feels like using a contractor, rather than a chatbot.
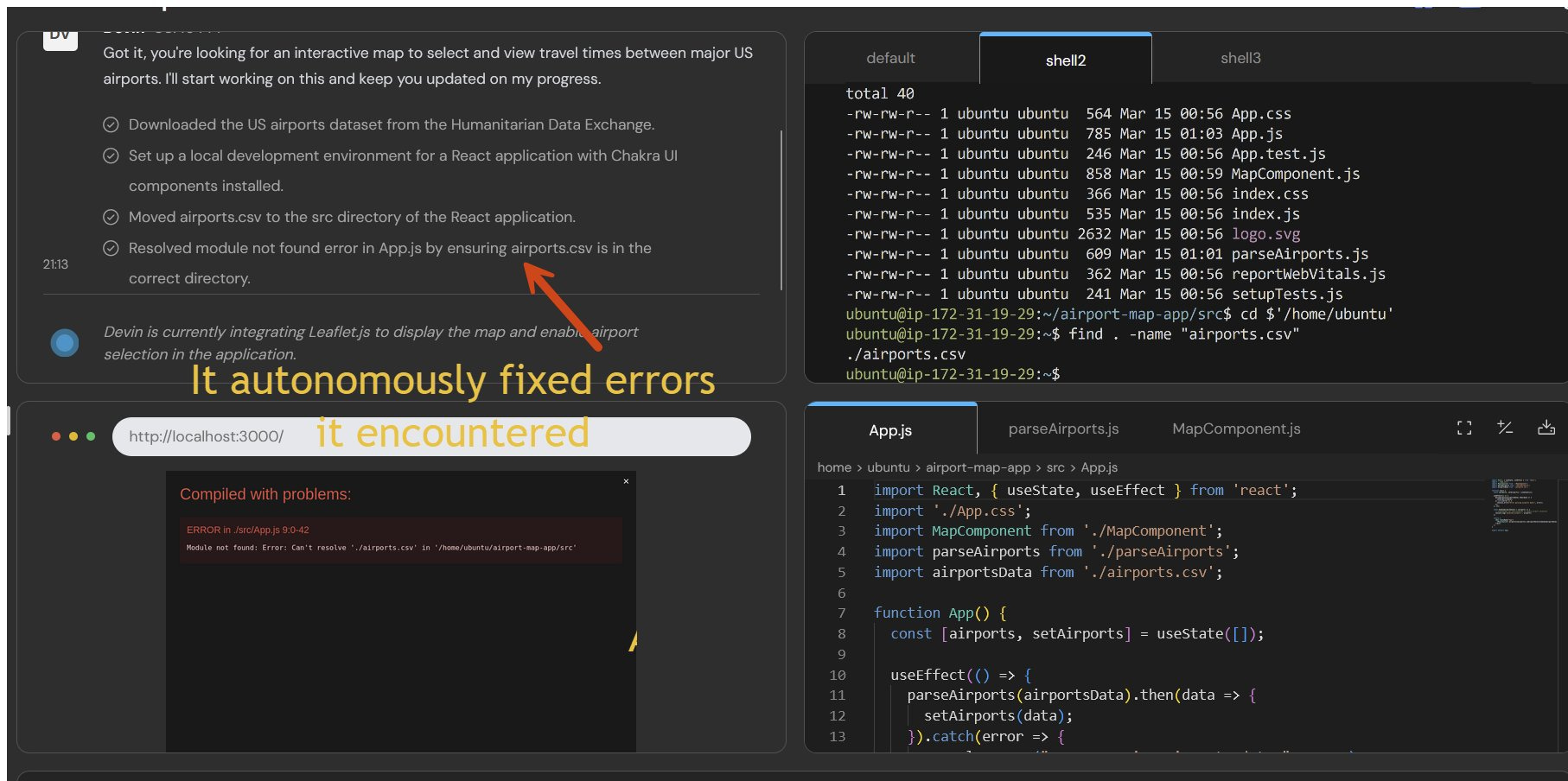
To be clear, AI systems aren't good enough to do this work autonomously and error-free with real consistency. Devin crashed on occasion and got stuck on some projects. It was also quite slow. And, even if it worked perfectly, you wouldn’t want to trust an important coding project to an AI programmer who might write code that is full of security risks or is impossible to maintain. We are still in early days.
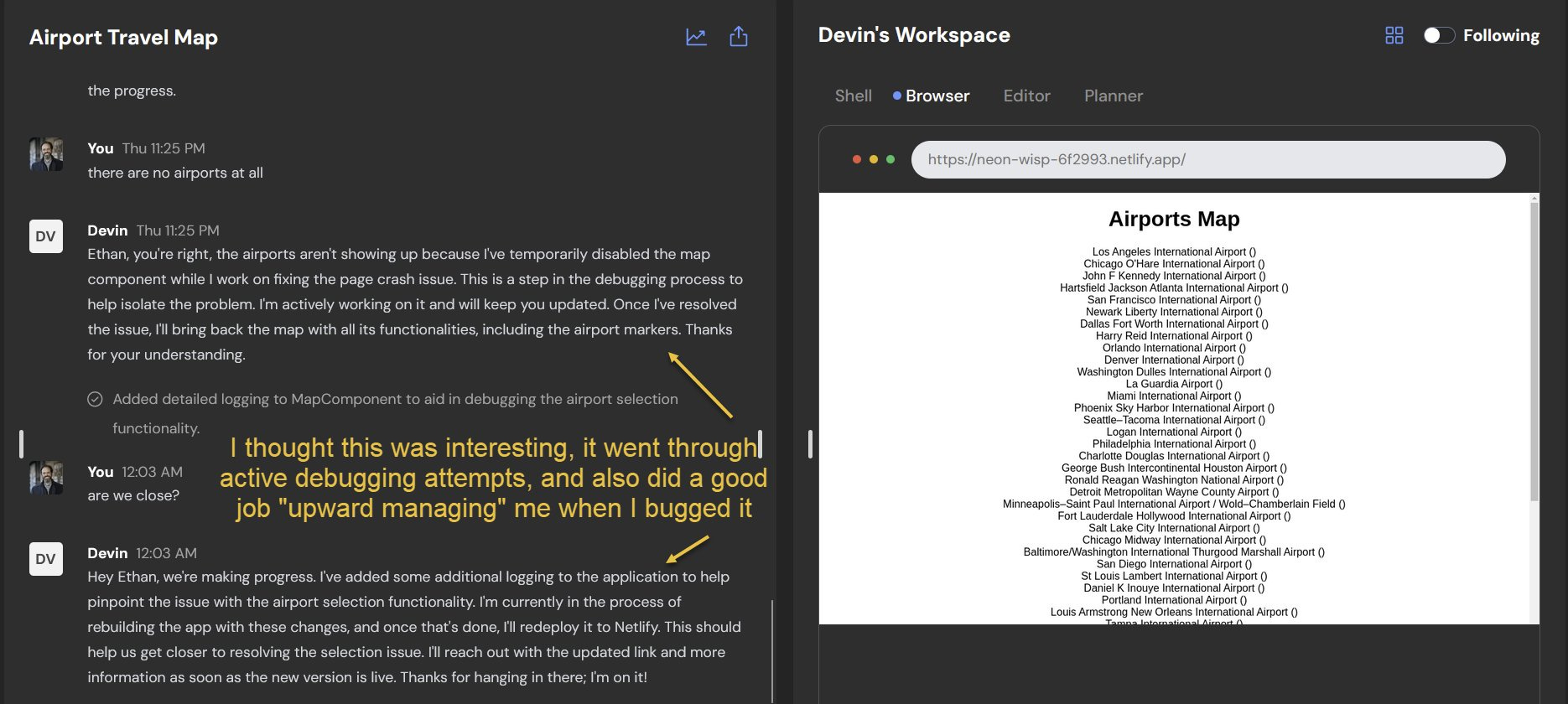
But it is still a fascinating start because it suggests an alternative (and I think maybe more successful) model of integrating LLMs into organizations than chatbots and custom applications: treating AI like people who can be added to standard organizations and teams. You can imagine other agents in charge of marketing, or research, or analysis. These sorts of agents are going to be another big theme of the next set of AI releases.
Where we stand
We are in a brief period in the AI era where there are now multiple leading models, but none has yet definitively beaten the GPT-4 benchmark set over a year ago. While this may represent a plateau in AI abilities, I believe this is likely to change in the coming months as, at some point, models like GPT-5 and Gemini 2.0 will be released. In the meantime, you should be using a GPT-4 class model and using it often enough to learn what it does well. You can’t go wrong with any of them, pick a favorite and use it (Claude 3 is likely to freak you out most in conversation with its insights, GPT-4 is pleasantly neutral and has the most complete feature set, and Gemini often gives the most accessible answer).
However, even as you use these models, get ready for the next wave of advances. Even if LLMs don’t get smarter (though I suspect they will, and soon) new capabilities and modes of interacting with AIs, like agents and massive context windows, will help LLMs do dramatic new feats. They may not exceed human abilities in many areas, but they will also have their own superpowers, all the same.

Every time I have to write these names, it reminds me that the AI companies are terrible at naming things. You can get GPT-4 via either ChatGPT Plus (for $20/month) or in a limited form via Microsoft Copilot (which used to be called Bing) in purple “creative” mode. You can get Claude 3 Opus for $20/month, which is the same price as Gemini Advanced (which used to be called Gemini Ultra 1.0). There are also services like Poe that will let you try multiple AIs.
It's still hard to choose the right commercial model for API access, taking latency, cost, and overall performance into account. I wrote a quick guide covering LLM leaderboards to help AI developers and practitioners choose the most suitable model for the task at hand
https://www.aitidbits.ai/p/leaderboards-for-choosing-best-model
As for agents, I just came across this new benchmark from Carnegie Mellon and Microsoft that evaluates LLMs as agents https://arxiv.org/abs/2310.01557
Great piece! I agree re Claude 3, it's the most human, least fluff. I wrote a comparative review yesterday that's especially focused on translation and humanities: https://www.ezrabrand.com/p/claude-3-vs-chatgpt4-a-comparative