
What people ask me most. Also, some answers.
A FAQ of sorts

I have been talking to a lot of people about Generative AI, from teachers to business executives to artists to people actually building LLMs. In these conversations, a few key questions and themes keep coming up over and over again. Many of those questions are more informed by viral news articles about AI than about the real thing, so I thought I would try to answer a few of the most common, to the best of my ability.
I can’t blame people for asking because, for whatever reason, the companies actually building and releasing Large Language Models often seem allergic to providing any sort of documentation or tutorial besides technical notes. I was given much better documentation for the generic garden hose I bought on Amazon than for the immensely powerful AI tools being released by the world’s largest companies. So, it is no surprise that rumor has been the way that people learn about AI capabilities.
In an attempt to address rumors, consider this a micro-FAQ on some of the questions I get asked most. Yet take my answers with a grain of salt: I make mistakes, the ground is shifting fast, and I may either be wrong already, or will soon be wrong, about some of these points. But that disclaimer doesn’t hold true for the first point, on AI detectors, where I feel very strongly about the answer:
Detecting AI
Can you detect AI writing?
No.
But what about AI writing detectors that claim to do that?
AI detectors don’t work. To the extent that they work at all, they can be defeated by making slight changes to text. And, what might be worse, they have high false positive rates and they tend to accuse people of using AI when they don’t use AI, especially students to whom English is a second language. The falsely accused have no recourse because they can’t prove they didn’t use AI.
You can’t detect AI writing automatically. Even OpenAI says you can’t.
But I am sure I am really good at detecting AI writing mysel-
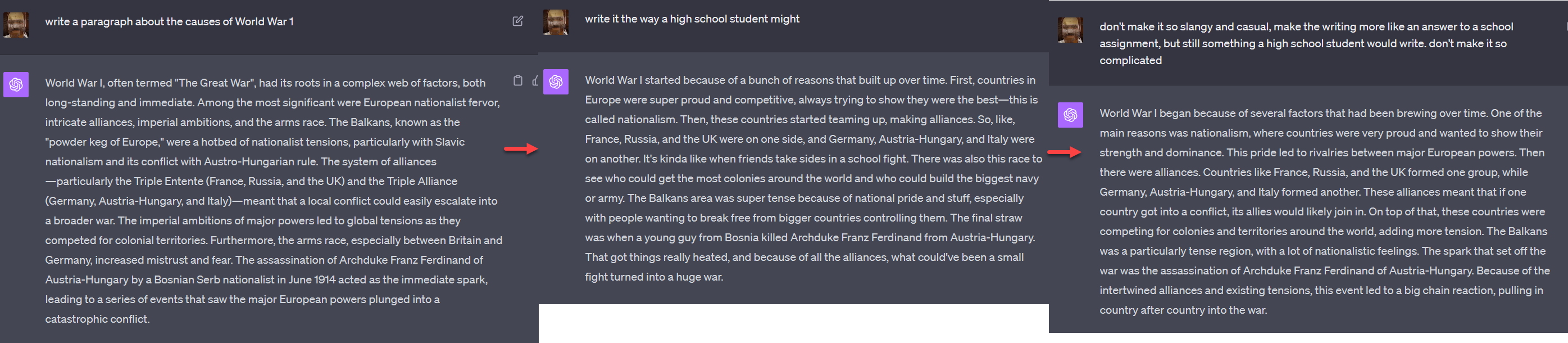
Look, I am going to cut you off here. You might think you are good at detecting AI writing, but you are just okay at detecting bad AI writing, and you combine that with your own biases and heuristics about who might be using AI. After a couple of prompts, AI writing doesn’t sound like generic AI writing.
I am sure that teachers who know their students well can guess at who might be cheating, as they always could, but you are going to miss a lot of cheaters who are doing it more subtly, which is a problem of fairness in and of itself.
I hate to say it, but homework as we know it is over, we educators are going to have to adjust. There are plenty of paths forward, but it is not going to include cheat-proof homework.
What about AI-generated images?
While there are more techniques to detect AI images, they are already very hard to identify just by looking, and in the long-term likely impossible. All the hints you think you know (bad fingers on hands, etc) are no longer true. Here’s an illustration: one of my innovation classes had students build a full board game with AI help (my syllabus now requires students to do at least one impossible thing for their project - if they can’t code, for example, I want working software). I took a picture of one of the teams showing off their game, and then generated three other images myself using Midjourney.

At a glance, without zooming in and examining every detail, which do you think is the real image? The answer will be in the comments…
Using AI
Who knows how to best use AI to help me with my work?
I have good news and bad news: the answer is probably nobody. That is bad news because there is no instruction manual out there that will tell you how to best apply AI to your job or school, so there is really no one to help you get the most out of this tool, or to teach you to avoid its specific pitfalls in your area of expertise. This can be challenging because AI has a Jagged Frontier - it is good at some tasks and bad at others in ways that are difficult to predict if you haven’t used AI a lot.
The good news is that, by using it a lot, you can figure out the best way to use AI. Then you have a valuable secret. You can decide whether you are going to share it with the world (my preference, hence this newsletter!) or keep it to yourself unless your organization incentivizes you to do otherwise.
So, what is the best way to get good at using AI?
If you are new to AI, you may find our free YouTube 5-part video series useful (it is built around an education context, but people have told me it was broadly helpful)
But, generally, my recommendation is to follow a simple two-step plan. First, get access to the most advanced and largest Large Language Model you can get your hands on. There are lots of AI models and apps out there, but, to get started, you don’t need to worry about them. Currently, there are only really three AIs to consider: (1) OpenAI’s GPT-4 (which you can get access to with a Plus subscription or via Microsoft Bing in creative mode, for free), (2) Google’s Bard (free), or (3) Anthropic’s Claude 2 (free, but paid mode gets you faster access). As of today, GPT-4 is the clear leader, Claude 2 is second best (but can handle longer documents), and Google trails, but that will likely change very soon when Google updates its model, which is rumored to be happening in the near future.
Then use it to do everything that you are legally and ethically allowed to use it for. Generating ideas? Ask the AI for suggestions. In a meeting? Record the transcript and ask the AI to summarize action items. Writing an email? Work on drafting it with AI help. My rule of thumb is you need about 10 hours of AI use time to understand whether and how it might help you. You need to learn the shape of the Jagged Frontier in your industry or job, and there is no instruction manual, so just use it and learn.
I do this all the time when new tools come out. For example, I just got access to DALL-E3, the latest image creation tool for OpenAI. It works very differently than other previous AI image tools because you tell ChatGPT-4 what you want, and the AI decides what to create. I fed it this entire article and asked it to create illustrations that would be good cover art. And here is what it came up with:

I found something AI can’t do, does that mean that it is outside the Jagged Frontier?
Maybe? But often better prompting, or enabling Advanced Data Analytics, or a different model, or a different approach can get the AI to solve a problem. I found that AI struggled filling in crossword puzzles, but a little while later Princeton Professor Arvind Narayanan figured out a way to get GPT-4 to do it. I wouldn’t feel too certain that a capability is outside the realm of AI until you have spent some time with different approaches.
And, if it is truly impossible for AI to do, wait a few months and try it again when a new model comes out.
Policy stuff
Before you read this, please note I am not a lawyer, so I asked the AI to read the material you are about to read and give me a disclaimer. Here it is:
Disclaimer (Generated by AI): The opinions and information expressed in this article are those of the author and do not necessarily reflect the views of any organizations or companies mentioned. This disclaimer itself was generated by an AI after reviewing the material. The information is presented for informational purposes only and should not be interpreted as legal, business, or any other form of professional advice. Readers are encouraged to conduct their own research and consult with professionals regarding any concerns or questions they may have.
Our company won’t let us use AI because we don’t want our data stolen, is that right?
There are lots of reasons to be concerned about the data sources for Large Language Models. No company is forthcoming about the training material that was used to build their AIs. It is likely that some, or maybe all, of the major LLMs have incorporated copyright material into their models. The data itself contains biases that make their way into the model in ways that can be difficult to detect. And human labor plays a role in part of the training process, which means both that more human biases can creep in, and also that low-wage workers in developing countries are exposed to toxic content in order to train the AI to filter it out.
All of these things are true… but the privacy issue that many people talk to me about is likely less of a barrier than you think. As a default, AI companies say they may use your interactions with their chatbots to refine their model (though it is extremely hard to extract any one piece of data from the AI, making direct data leaks unlikely), but it is relatively easy to get more privacy. Individual users of ChatGPT can turn on a privacy mode where the company says they will not retain or train AI your data. But large organizations have even more options, including HIPAA compliant versions of the major AIs. All the big AI companies want organizations to work with them, so it is not surprising that all of them are eager to offer data guarantees. The short answer is that data privacy is probably not as big a concern as it might seem at first glance.
What’s the deal with copyright and AI?
Again, not a lawyer, but, as I understand it, current US copyright rules around AI material are sort of unclear and in flux. However, large AI companies seem eager to ensure their customers that using their AI output commercially is safe. For example, Adobe and Microsoft offer legal guarantees that if you are sued over the output of their AIs, they will protect you (at least under some circumstances). But also remember that legal use isn’t always going to be ethical use, especially as we consider cases where AI work displaces human labor or produces art “in the style” of a living artist.
The Future
Aren’t AIs like GPT-4 getting worse with time?
No, this turned out to be an incorrect conclusion from a working paper examining the performance of AI on certain math problems. Crossword solver Prof. Arvind Narayanan and Prof. Sayash Kapoor (who have an excellent Substack that I occasionally disagree with but always find valuable), found that AI models are not getting worse at these sorts of problem, but they are changing, which alters the way you need to prompt the AI. You see, what you call GPT-4 or Bard or Bing today is not the same thing as what Bard or Bing or GPT-4 was a few months ago. Models are continually getting additional training and tuning that improves performance in some ways, while also changing behavior in others. It is part of why it is so hard to treat AIs like normal software, and sometimes easier to treat it like a person, even though it isn’t.
Won’t AI development ground to a halt as the internet fills with AI data? Or as it runs out of data to train on?
I hear this a lot. It may be true, this paper argues that we will be out of training data in the next decade or two (or even by 2026 if we restrict ourselves to high quality data). And this paper suggests that AI models will indeed start to struggle as the web fills up with AI content. But many computer scientists argue that neither of these are actually long-term problems, and offer various solutions, including ways of training AIs on data that the AI makes up.
Ultimately, these issues are unlikely to stop LLMs from improving over the next couple years, which I think is what people are really asking when they ask me this question.
How good does AI get?
Honestly, I have no idea. And I suspect no one else does either, given the debates among prominent AI experts. Right now, models get better as they get larger, which requires more data and more computers and more money. At some point, technical, economic, or regulatory limits are likely to kick in and slow the advance of AI. But, at the same time, there is a lot of experimentation on how to make smaller models perform like bigger ones, and similar experiments on how to make larger models perform even better. I suspect there is a lot of room left for rapid improvement.
What all of this means is absolutely unclear. Do we reach the feared/longed-for level of Artificial General Intelligence, where AIs are smarter than humans (thus, depending on who you ask, creating a machine that will start saving, killing, or ignoring humanity)? Do we “just” get order of magnitude improvements in AIs that are already performing at high human levels on many tasks? Do AIs stop improving quickly? There is no clear consensus, which, uncomfortably, means that we should be thinking about all three scenarios. The only thing I know for sure is that the AI you are using today is the worst AI you are ever going to use, since we are in for at least one major round of AI advances, and likely many more.
I realized revealing the answer now will ruin the survey, so I'll add it here in a few hours.
I love that closing sentence: "The only thing I know for sure is that the AI you are using today is the worst AI you are ever going to use."
Also, I wanted to address an earlier point about the internet being a finite source of content for AI training, and using AI-generated content to bypass that. There's a potential phenomenon called model collapse that might occur if LLM output becomes too strongly the primary source of information that subsequent generations are trained on. Paper here: https://arxiv.org/abs/2305.17493
but TLDR version: the probable gets overrepresented, and the improbable (but real) slowly gets erased. Based on the probabilistic way that these large models work, this makes a lot of sense-- but a probable reality and an actual reality are two extremely different things.
LLMs and LMMs (large multimodal models) are likely to improve for quite a while yet, but it's quite possible that it will not be a linear or even exponential direction upwards. There will probably be some hidden valleys of performance loss that we might not notice until we solve them with novel architectures (if we ever even notice them at all!)
So I'll close with a sentiment that echoes yours: "The only thing I know for sure is that the AI you are using today is the worst AI you are ever going to use - but the same thing might not be true in the future."