
The recent history of AI in 32 otters
Three years of progress as shown by marine mammals

Two years ago, I was on a plane with my teenage daughter, messing around with a new AI image generator while the wifi refused to work. Otters were her favorite animal, so naturally I typed: “otter on a plane using wifi” just as the connection was restored. The resulting thread went viral and “otter on a plane using wifi” has since become one of my go-to tests of progress AI image generation.

What started as a silly prompt has become my accidental benchmark for AI progress. And tracking these otters over the years reveals three major shifts in AI over the past few years: the growth of multiple types of AI tools, rapid improvement, and the status of local and open models.
Diffusion models
The first otters I created were made with image generation tools. For most of the very recent history of AI, image generation used a process called diffusion, which works fundamentally differently from Large Language Models like ChatGPT. While LLMs generate text one word at a time, always moving forward, diffusion models start with random static and transform the entire image simultaneously through dozens of steps. It is like the difference between writing a story sentence by sentence versus starting with a marble block and gradually sculpting it into a statue, every part of the image is being refined at once, not built up sequentially. Instead of predicting "what comes next?" like a language model, diffusion models predict "what should this noise become?" and transform randomness into coherent images through repeated refinement.
There are a number of diffusion models out there, but I have tended to use Midjourney, which has been around longer than many other AI tools. Using Midjourney allows us to see how diffusion models have developed over time, as you can see with the simple prompt “otter on a plane using wifi” (for every image and video in this post, I pick the best out of the first four images generated). We go from melted fur at the start of 2022 to a visible otter (with too many fingers and a weird keyboard) at the end of that year. In 2023, we get a photorealistic otter, but still a weird keyboard and plane windows. In 2024, the lighting and positioning become better, and by 2025 we have excellent photorealism.

But what makes diffusion models interesting is not their increasing ability to make photorealistic images, but rather the fact that they can create images in various styles. This cuts to the heart of why AI image generation is so controversial, as many AI models are trained on images from throughout the web, including copyrighted work, and can thus replicate images in the style of living artists without their permission or compensation. But you can see how this works when applied to older artists and styles. Here is “otter on a plane using wifi” in the style of the Bayeux Tapestry, Egon Schiele, street art graffiti, and a Japanese Ukiyo-e print. (The wider your knowledge of art history, the more you can make these image creators do).

Diffusion models are not limited to existing styles. Midjourney lets any creator train the model to create images in a style they like and then share those unique “style codes.” If I end a prompt with one of these style codes, I get very different results: ranging from cyberpunk otters to cartoon ones.

I want to show you one last diffusion image, but this one is fundamentally different. I created it on my home computer using Flux. Unlike proprietary AI models like Midjourney or ChatGPT that run in corporate data centers, open weights models can be downloaded, modified, and run by anyone, anywhere. This high-quality image wasn't generated by a tech giant's servers but by the graphics card on my PC (you can also see ComfyUI, the interface I used to generate the image). It is remarkably close to the quality of the best closed-source models.
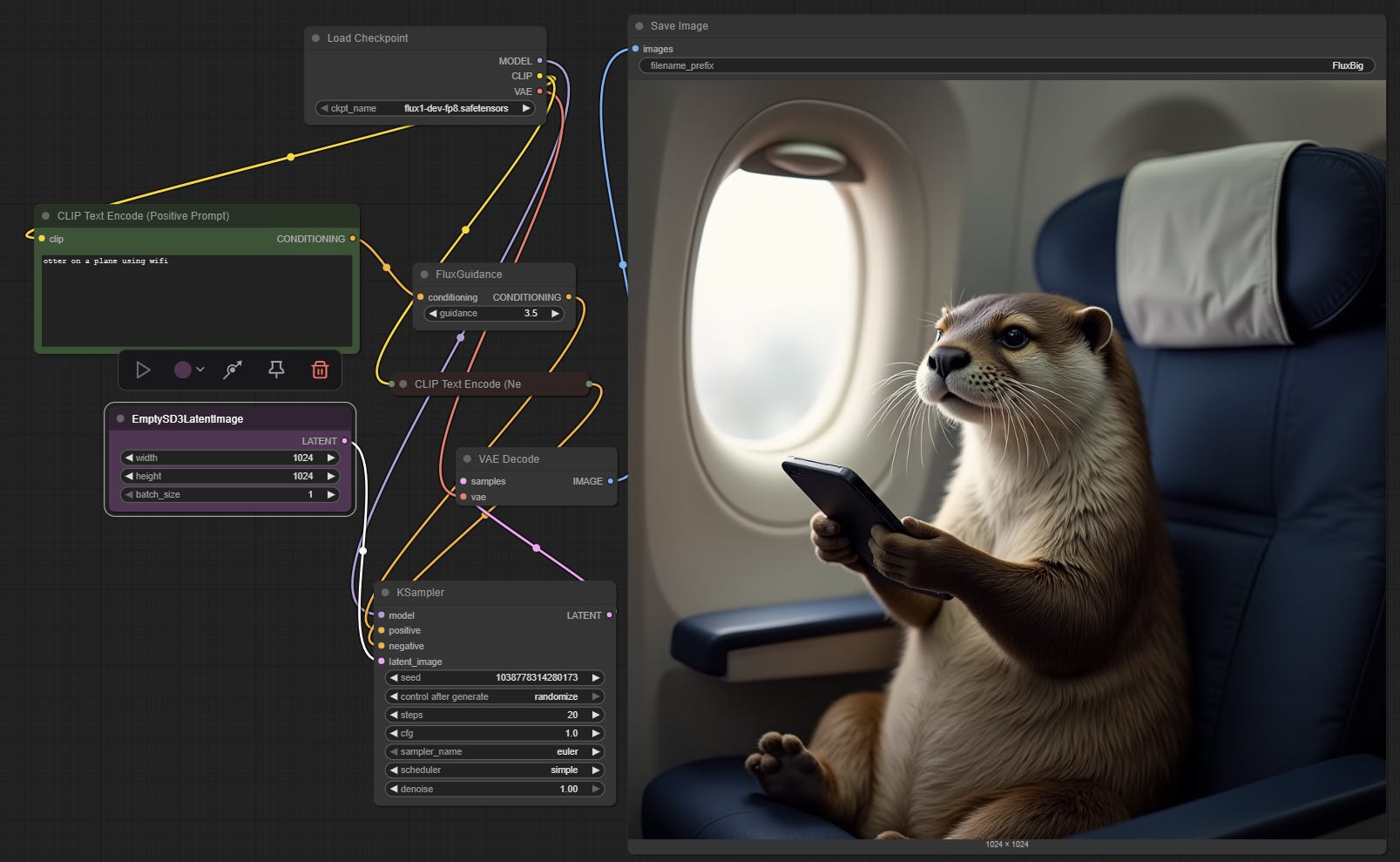
Whether open or proprietary, diffusion models tend to produce pretty random results, and creating a single quality image can often take multiple tries. The latest diffusion models (like Google’s Imagen 4) do better, but there is still a lot of luck and trial-and-error involved in a good output.
Multimodal Image Generation
For most of the era of Large Language Models, when an LLM like ChatGPT created an image, it was actually calling on one of these diffusion models to make the image and show the results. Because this was all done indirectly (the LLM prompted the diffusion model which created the image), the process of creating an image seemed even more random than working with a standard image generator.
That changed with the release of multimodal image generation by OpenAI and Google in the past couple months. Unlike diffusion models that transform noise into images, multimodal generation lets Large Language Models directly create images by adding tiny patches of color one after another, just as they add words one after another. This gives AIs deep control over the images it creates. Here is "an otter on an airplane using wifi, on their laptop screen is image generation software creating an image of an otter on a plane using wifi," on my very first attempt.

But now I have to confess something: my daughter's favorite animal is not just any otter, it is the sea otter, and every single image so far has been of the much more common river otter. Finally, with multimodal generation, I could vindicate myself as a father, as multimodal models can make specific changes and adjustments: "make it a sea otter instead, give it a mohawk, they should be using a Razer gaming laptop."

I still use Midjourney and Imagen when I am trying to achieve a visual impact and when I am willing to spend a lot of time working through randomized images, but if I want a particular picture, I now always turn towards multimodal image generators. I suspect they will become increasingly common. As of yet, there are no open weights multimodal image generators, but that is likely to change soon.
Using Code for Images and “Sparks”
Multimodal generation shows AI can control images with precision. But there's a deeper question: does AI actually understand what it's creating, or is it just recombining patterns from training data? To test true spatial reasoning, we can force AI to draw using code - no visual feedback, no pre-trained image patterns to lean on. It's like asking someone to paint blindfolded using only mathematical instructions.
One particularly challenging type of code to use to draw is TikZ, a mathematical language used for producing scientific diagrams in academic papers. It is so ill-suited to the purpose that the name TikZ stands for the recursive German phrase "TikZ ist kein Zeichenprogramm" (“TikZ is not a drawing program”). Because of that, there is very little training data on using TikZ for drawings, meaning the AI cannot “remember” code from its training, it has to make it up itself. Creating an image with pure math in this language is a difficult job. In fact, a TikZ drawing of a unicorn by the now obsolete GPT-4 was considered, in a hugely influential paper, to be a sign that LLMs might have a “spark” of AGI - otherwise how could it be so creative? Here is how that unicorn looked, for reference:

I had a little less luck getting the old GPT-4 to draw an otter on a plane using wifi:

But what happens if we ask a more recent model, like Gemini 2.5 Pro, to draw our otter with TikZ? It isn’t perfect (and Gemini took “on a plane” literally and made the otter sit on the wing), but if the pink unicorn showed a spark this certainly represents a larger leap.

And open weights models are catching up here as well, though they generally remain a few months behind the frontier. The new version of DeepSeek r1, probably the best open weights model available, produces a TikZ otter that is not quite as good as the closed source models like Gemini, but I expect that it will continue to improve.

These drawings themselves aren’t as important as the fact that models are reasoning about spatial relationships from scratch. That is why the authors of the “Sparks” papers suggested these systems aren't just pattern-matching from training data but developing something closer to actual understanding.
Video
If still images show impressive progress, video generation reveals just how fast AI is accelerating. This was an “otter on a plane using wifi on a computer” as generated by the best available video generator of July, 2024, Runway Gen-3 alpha.
And this is in Google’s Veo 3 with the same prompt “otter on a plane using wifi on a computer” in 2025, less than a year later. Yes, the sound is 100% AI generated as well.
And, continuing the theme, there are now open weights AI models that can run on my home computer that are behind the state-of-the-art, but catching up. Here are the results from Tencent’s HunyuanVideo for the same prompt. Yes, it's hideous - but this is made on my home computer, not a massive data center.
What this all means
The otter evolution reveals two crucial trends with some big implications. First, there clearly continues to be rapid improvement across a wide range of AI capabilities from image generation to video to LLM code generation. Second, open weights models, while not generally as good as proprietary models, are often only months behind the state-of-the-art.
If you put these trends together, it becomes clear that we are heading towards a place where not only are image and video generations likely to be good enough to fool most people, but that those capabilities will be widely available and, thanks to open models, very hard to regulate or control. I think we need to be prepared for a world where it is impossible to tell real from AI-generated images and video, with implications for a wide swath of society, from the entertainment we enjoy to our trust for online content.
That future is not far away, as you can see from this final video, which I made with simple text prompts to Veo 3. When you are done watching (and I apologize in advance for the results of the prompt “like the musical Cats but for otters”), look back at the first Midjourney image from 2022. The time between a text prompt producing abstracts masses of fur and those producing realistic videos with sound was less than three years.
I didn't mention it in the post but given discussions on social media, it is worth noting the the environmental impact of an individual image is negligible, while in aggregate it it obviously compounds.
The MIT Technology Review found that generating an image took 2,282 joules, which is equivalent to 5 seconds running a microwave or 14 seconds of a laptop. https://www.technologyreview.com/2025/05/20/1116327/ai-energy-usage-climate-footprint-big-tech/
What's more frightening -- the threat of AI domination or the prospect of the Otters musical?