
Something New: On OpenAI's "Strawberry" and Reasoning
Solving hard problems in new ways

I have had access to the much-rumored OpenAI “Strawberry” enhanced reasoning system for awhile, and now that it is public, I can finally share some thoughts1. It is amazing, still limited, and, perhaps most importantly, a signal of where things are heading.
The new AI model, called o1-preview (why are the AI companies so bad at names?), lets the AI “think through” a problem before solving it. This lets it address very hard problems that require planning and iteration, like novel math or science questions. In fact, it can now beat human PhD experts in solving extremely hard physics problems.
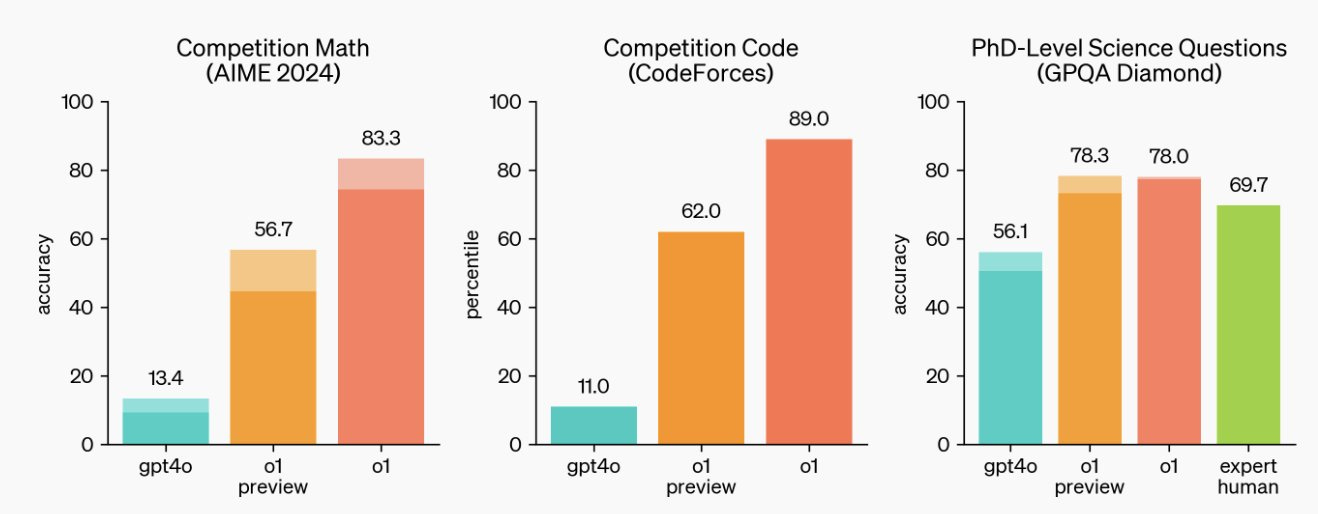
To be clear, o1-preview doesn’t do everything better. It is not a better writer than GPT-4o, for example. But for tasks that require planning, the changes are quite large. For example, here is me giving o1-preview the instruction: Figure out how to build a teaching simulator using multiple agents and generative AI, inspired by the paper below and considering the views of teachers and students. write the code and be detailed in your approach. I then pasted in the full text of our paper. The only other prompt I gave was build the full code. You can see what the system produced below.
Strawberry in Action
But it is hard to evaluate all of this complex output, so perhaps the easiest way to show the gains of Strawberry (and some limitations) is with a game: a crossword puzzle. I took the 8 clues from the upper left corner of a very hard crossword puzzle and translated that into text (because o1-preview can’t see images, yet). Try the puzzle yourself first; I am willing to bet that you find it really challenging.

Crossword puzzles are especially hard for LLMs because they require iterative solving: trying and rejecting many answers that all affect each other. This is something LLMs can’t do, since they can only add a token/word at a time to their answer. When I give the prompt to Claude, for example, it first comes up with an answer for 1 down (it guesses STAR, which is wrong) and then is stuck trying to figure out the rest of the puzzle with that answer, ultimately failing to even come close. Without a planning process, it has to just charge ahead.

But what happens when I give this to Strawberry? The AI “thinks” about the problem first, for a full 108 seconds (most problems are solved in much shorter times). You can see its thoughts, a sample of which are below (there was a lot more I did not include), and which are super illuminating - it is worth a moment to read some of it.

The LLM iterates repeatedly, creating and rejecting ideas. The results are pretty impressive, and it does well… but o1-preview is still seemingly based on GPT-4o, and it is a little too literal to solve this rather unfair puzzle. The answer to 1 down “Galaxy cluster” is not a reference to real galaxies, but rather a reference to the Samsung Galaxy phone (this stumped me, too) - “APPS.” Stuck on real galaxies, the AI instead kept trying out the name of actual galactic clusters before deciding 1 down is COMA (which is a real galactic cluster - I had no idea). Thus, the rest of the results are not correct and do not fit the rules exactly, but are pretty creative: 1 across is CONS, 12 across is OUCH, 15 across is MUSICIANS, etc.
To see if we could get further, I decided to give it a clue: “1 down is APPS.” The AI takes another minute. Again, in a sample of its thinking (on the left) you can see how it iterates ideas.

The final answer here is completely correct, solving all the hard references, though it does hallucinate a new clue, 23 across, which is not in the puzzle I gave it.

So o1-preview does things that would have been impossible without Strawberry, but it still isn’t flawless: errors and hallucinations still happen, and it is still limited by the “intelligence” of GPT-4o as the underlying model. Since getting the new model, I haven’t stopped using Claude to critique my posts - Claude is still better at style - but I did stop using it for anything involving complex planning or problem solving. It represents a huge leap in those areas.
From Co-Intelligence to…
Using o1-preview means confronting a paradigm change in AI. Planning is a form of agency, where the AI arrives at conclusions about how to solve a problem on its own, without our help. You can see from the video above that the AI does so much thinking and heavy lifting, churning out complete results, that my role as a human partner feels diminished. It just does its thing and hands me an answer. Sure, I can sift through its pages of reasoning to spot mistakes, but I no longer feel as connected to the AI output, or that I am playing as large a role in shaping where the solution is going. This isn’t necessarily bad, but it is different.
As these systems level up and inch towards true autonomous agents, we're going to need to figure out how to stay in the loop - both to catch errors and to keep our fingers on the pulse of the problems we're trying to crack. o1-preview is pulling back the curtain on AI capabilities we might not have seen coming, even with its current limitations. This leaves us with a crucial question: How do we evolve our collaboration with AI as it evolves? That is a problem that o1-preview can not yet solve.
The usual reminder - I am not paid or compensated in any way by any AI company. OpenAI was not shown this piece before I published it (nor did they ask). I did not know when the model was going to be released in advance.
Thanks for this. It's rather unsettling to hear you question the future of "co-intelligence." Still, I admire you for not twisting data to fit your thesis. Cheers, Clay
Another insightful post from Ethan Mollick today. I appreciate what he wrote in his final paragraph. Heads up ...
---
As these systems level up and inch towards true autonomous agents, we're going to need to figure out how to stay in the loop - both to catch errors and to keep our fingers on the pulse of the problems we're trying to crack. o1-preview is pulling back the curtain on AI capabilities we might not have seen coming, even with its current limitations. This leaves us with a crucial question: How do we evolve our collaboration with AI as it evolves? That is a problem that o1-preview can not yet solve.
---