


Superhuman?
What does it mean for AI to be better than a human? And how can we tell?

The explicit goal of many of the most important AI labs on the planet is to achieve Artificial General Intelligence (AGI), an ill-defined term that can mean anything from “superhuman machine god” to the slightly more modest “a machine that can do any task better than a human.”
Given that this is the aim of the companies training AI systems, I think it is worth taking seriously the question of when, if ever, we might achieve AGI - “a machine that beats humans at every possible task.” Most computer scientists seem to think this sort of AGI is possible but divide deeply (surprise!) over approaches and timelines. The average expected date for achieving AGI in a 2023 survey of computer scientists was 2047, but the same survey also gave a 10% chance AGI would be achieved by 2027.
No matter what happens next, today, as anyone who uses AI knows, we do not have an AI that does every task better than a human, or even most tasks. But that doesn’t mean that AI hasn’t achieved superhuman levels of performance in some surprisingly complex jobs, at least if we define superhuman as better than most humans, or even most experts. What makes these areas of superhuman performance interesting is that they are often for very “human” tasks that seem to require empathy and judgement. For example:
If you debate with an AI, they are 87% more likely to persuade you to their assigned viewpoint than if you debate with an average human
GPT-4 helps people reappraise a difficult emotional situation better than 85% of humans, beating human advice-givers on the effectiveness, novelty, and empathy of their reappraisal.
GPT-4 generates startup ideas that outside judges find to be better than those of trained business school students.
149 actors playing patients texted live with one of 20 primary care doctors or else Google's new medical LLM. The AI beat the primary care doctors on 28 out of 32 characteristics, and tied on the other four, as rated by human doctors. From the perspective of the "patients," the AI won on 24 of 26 scales of empathy and judgement.
There are other examples, but these serve to illustrate the point. For some tasks, today’s AI already exceeds human performance, which is astonishing, but, as my coauthors and I discussed in our paper on the Jagged Frontier of AI, the abilities of AI are uneven, even within a single job. The AI generates great startup ideas but struggles to code complex products without human help. GPT-4 can give good medical diagnoses but can also mess up simple math if you want it to write a prescription. This is why, for now, AI works best as a co-intelligence, a tool humans use to augment their own performance, especially once they understand the shape of the Jagged Frontier.
But, again, this is AI today. The major AI companies want to push the Frontier further and further until AI is better than every human at every task. This raises a lot of issues, but also some obvious questions: how do we know what AI is actually good at? And how do we know how fast it is improving?
Testing for Superhumanity
One way to do this is just to give AI tests made for humans. That is exactly what OpenAI did upon the release of GPT-4, showcasing the big differences between GPT-3.5 (the free version of ChatGPT that you really shouldn’t be using anymore) and GPT-4 (the paid version of ChatGPT). The vertical axis is not the test score, but the percent of human test takers beaten by the AI. Pretty impressive!
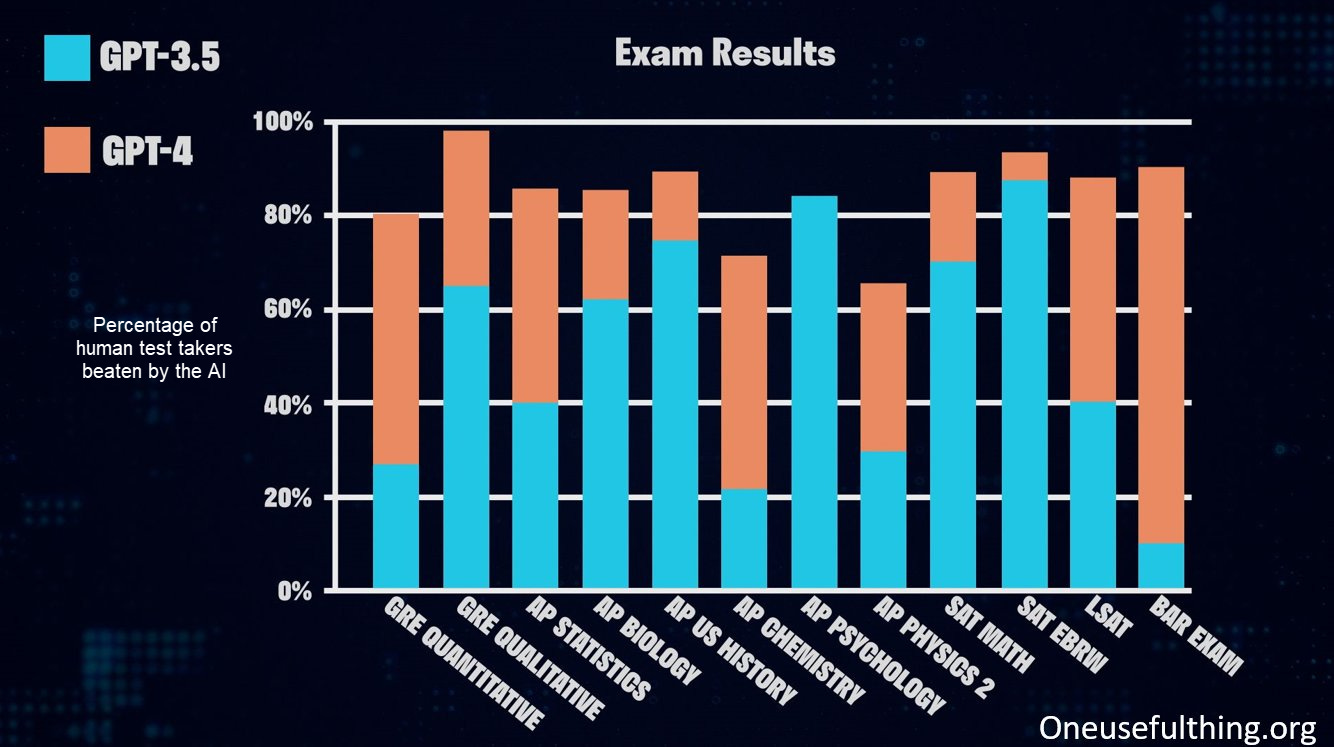
…but also a bit misleading. First off, it is very easy to imagine that the questions for some of these tests were included in the AI training data, effectively allowing it to “memorize” the answers in advance (an issue called “overfitting”). Second, the nature of giving AIs human exams overall is quite fraught. Take the fact that the AI scores in the 90th percentile in the Bar Exam. A new paper examining this score in more detail finds a number of problems with how the AI is compared to humans, and ultimately concludes that, with the right prompting, GPT-4 would be in the 69th percentile overall (not the 90th) and is in the 48th percentile of students who pass the exam. Still a very good grade, and one that passes the Bar, but not quite as good as reported. And tests remain a limited measure, as passing the Bar does not make you a good lawyer.
Another issue with one-off tests is that they don’t help us understand if AI is broadly getting closer to AGI. For that, we need benchmarks over time. The field of AI has a lot of benchmarks, and they are mostly pretty idiosyncratic. Almost all of them focus on either coding skills (AI labs are full of coders, so they think a lot more about AI coding skills than almost any other skill) or on tests of general knowledge. Probably the most common is the MMLU, a sort of hard quiz on a variety of topics (more details in a moment), and a test many AIs have been given1. Humans who are not specialists score 35% on the test, and experts apparently score 90% in their fields. That lets us visualize, thanks to the work of Maxime Labonne, the trends in AI ability over time compared to human level. This graph is important because you can see four key facts:
There are a lot of LLMs, the ones you probably have heard of like GPT-4, Gemini, and Claude, but also a ton of other models, most of which are “open weights,” which is sort of like open source. Anyone can download and use open weights models freely, and they are being developed in many places, with notable models including Qwen (China), Mixtral (France), and Falcon (Abu Dhabi). The dominant open weights player right now is Meta, with its powerful Llama 3 models.
You can see the impact of the scaling laws of AI: the larger the AI model (meaning requiring more data and more training time), the better the AI is. AIs are getting larger and better rapidly over time, beating amateur answers and approaching expert levels.
GPT-4 was an outlier when it came out, far above any other model, but has been joined by the two other GPT-4 class models, Gemini Advanced and Claude 3 Opus. It is possible (but, from insiders I speak to, unlikely) that GPT-4 represents some sort of upper bounds of ability for AI, but we will learn more soon as new models are released.
Closed source, proprietary models controlled by Google, Anthropic, and OpenAI are the best performers, with open weight models lagging quite a ways behind. (But Meta’s largest version of its open weights Llama 3 model gets as high as 86% on the MMLU, making it GPT-4 class, but it has not been released yet).
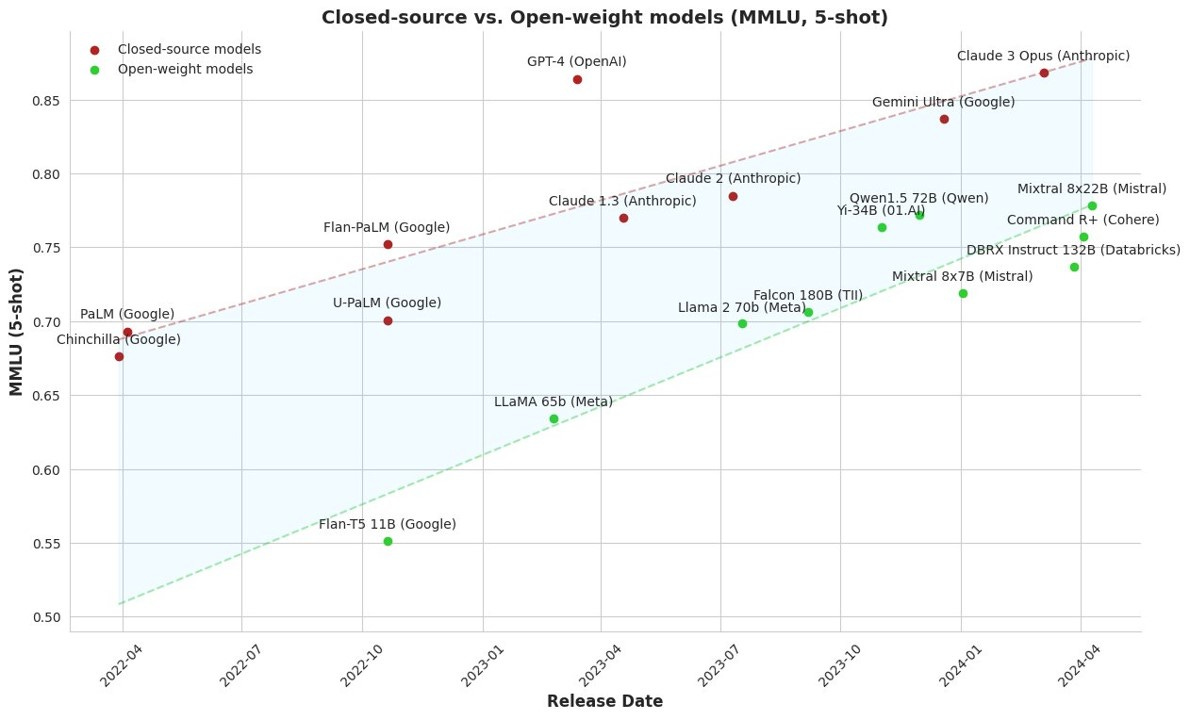
But here, again, reality is complicated. We have the same issue of AIs potentially being trained on test questions, either by accident or so they can score highly on these benchmarks. And the MMLU is a super weird test full of very hard, very specific problems - you can try taking them yourself here - making it unclear what it measures. The test itself is uncalibrated, meaning we don’t know if moving from 84% correct to 85% is as challenging as moving from 40% to 41% correct. And the actual top score may be unachievable because there many errors in the test questions.

Every available AI benchmark has its own similar set of problems, and yet, in aggregate, they show us something interesting.
Up and To the Right
To see why, we can turn to the Arena Leaderboard. This is a site that lets you put in a prompt and compare the two answers of two different LLMs (it’s fun, you should try it using the link). It is also a fairly good way to compare models, since it measures “vibes” - how good the models are across over a million conversations, subjectively. The site uses the ELO rating system, originally developed for ranking chess players, to compare the performance of different language models based on user preferences. Below you can see how the models stack up in terms of win rates. Even though the measure is very different than MMLU, the results are very similar. In fact, I took a sample of 10 of the LLMs on the list and found ELO and MMLU were very highly correlated (.89).
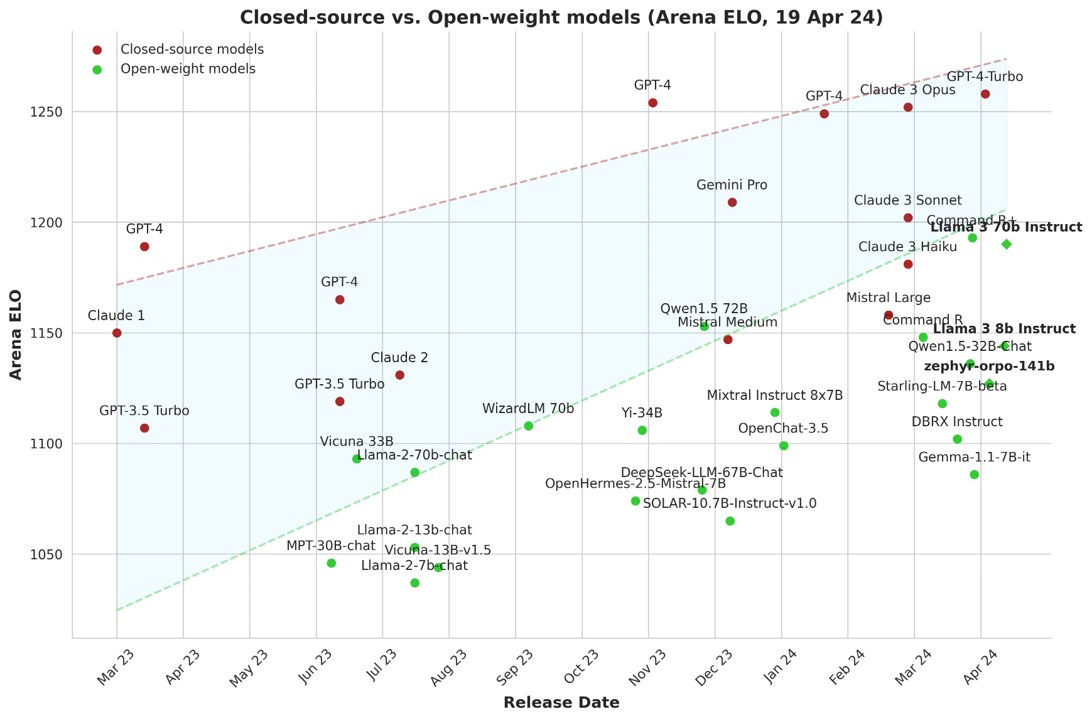
So there does seem to be some underlying ability of AI captured in many different measures, and when you combine those measures over time, you see a similar pattern - everything is moving up and to the right, approaching, often exceeding human level performance.
Zoom out, and the pattern is clear. Across a wide range of benchmarks, as flawed as they are, AI ability gains have been rapid, quickly exceeding human-level performance.

As long as the scaling laws of training Large Language Models continues to hold, the way it has for several years, this rapid increase is likely to continue. At some point, development will hit a wall because of increasing expense or a lack of data, but it isn’t clear when that might happen, and recent papers suggest that many of these obstacles might be solvable. The end of rapid increases could be imminent, or it could be years away. Based on conversations with insiders in several AI labs, I suspect that we have some more years of rapid ability increases ahead of us, but we will learn more soon.
Alien vs. Human
The increasing ability of AI to beat humans across a range of benchmarks is a sign of superhuman ability, but also requires some cautious interpretation. AIs are very good at some tasks, and very bad at others. When they can do something well - including very complex tasks like diagnosing disease, persuading a human in a debate, or parsing a legal contract - they are likely to increase rapidly in ability to reach superhuman levels. But related tasks that human lawyers and doctors perform may be completely outside of the abilities of LLMs. The right analogy for AI is not humans, but an alien intelligence with a distinct set of capabilities and limitations. Just because it exceeds human ability at one task doesn’t mean it can do all related work at human level. Although AIs and humans can perform some similar tasks, the underlying “cognitive” processes are fundamentally different.
What this suggests is that the AGI standard of “a machine that can do any task better than a human” may both blind us to areas where AI is already better than a human, and also make humans seem more replaceable than we are. Until LLMs get much better, having a human working as a co-intelligence with AI is going to be necessary in many cases. We might want to think of the development of AGI in tiers:
Tier 1: AGI: “a machine that can do any task better than a human.”
Tier 2: Weak AGI: at this level, a machine beats an average human expert at all the tasks in their job, but only for some jobs. There is no current Weak AGI system in the wild but keep your eyes on some aspects of legal work, some types of coaching, and customer service.
Tier 3: Artificial Focused Intelligence: AIs beat an average human expert at a clearly defined, important, and intellectually challenging task. Once AI reaches this level, you would rather consult an AI to get help with this matter than a random expert, though the best performing humans would still exceed an AI. We are likely already here for aspects of medicine, writing, law, consulting, and a variety of other fields. The problem is that a lack of clear specialized benchmarks and studies means that we don’t have good comparisons with humans to base our assessments of AI on.
Tier 4: Co-Intelligence: Humans working with AI often exceed the best performance of either alone. When used properly, AI is a tool, our first general-purpose way of improving intellectual performance. It can directly help us come up with new strategies and approaches, or just provide a sounding board for our thoughts. I suspect that there are very few cognitively demanding jobs where AI cannot be of some use, even if it just to bounce ideas off of.
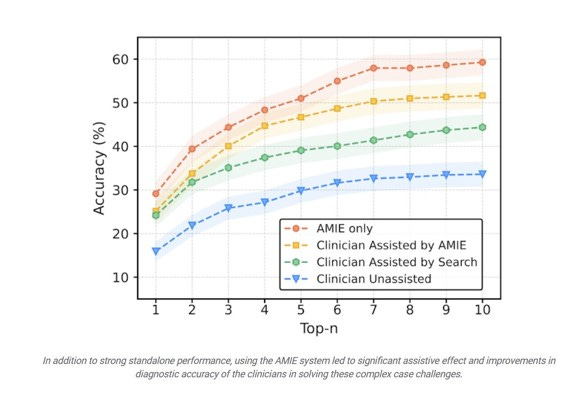
Even though tests and benchmarks are flawed, they still show us the rapid improvement in AI abilities. I do not know how long co-intelligence will dominate over AI agents working independently, because in some areas, like diagnosing complex diseases, it appears that adding human judgement actually lowers decision-making ability relative to AI alone. We need expert-established benchmarks across fields (not just coding) to get a better understanding of how these AI abilities are evolving. I would love to see large-scale efforts to measure AI abilities across academic and professional disciplines, because that may be the only way to get a sense of when we are approaching AGI.
Even without formal measurement approaches, as AI continues to surpass human abilities in specific domains, we can expect to see significant disruptions across industries, from healthcare and law to finance and beyond. The rise of Artificial Focused Intelligence and co-intelligence systems will likely lead to increased productivity and efficiency, but it may also require some re-evaluation about the role of humans in decision-making. While the path to true AGI remains uncertain, a more general cognitive revolution is well underway, and its impact will be felt widely.

Even how the MMLU is taken is complicated, with different models prompted in different ways. The “5-shot” in the name refers to the fact that the AI is given five example questions in the prompt, which makes it more accurate at multiple choice questions. Adding to the confusion, there are different versions of the MMLU. It is all pretty messy.
If AI is becoming SUPER-human, then maybe we should be focusing on becoming super-HUMAN
For what it's worth, I strongly suspect AI experts are, shall we say, a bit naive in how they think about human ability and put far too much stock in all those benchmarks originally designed to gauge human ability. Those tests were designed to differentiate between humans in a way that's easy to measure. And that's not necessarily a way to probe human ability deeply. Rodney Brooks on The Seven Deadly Sins of Predicting the Future of AI has some interesting remarks on performance and competence that are germane: https://disq.us/url?url=https%3A%2F%2Frodneybrooks.com%2Fthe-seven-deadly-sins-of-predicting-the-future-of-ai%2F%3AzD97WNZ6Jg6Q9ou45kbO_Odgs0A&cuid=2539338
I've written an article in which I express skepticism about that ability of AI "expert" to gauge human ability: Aye Aye, Cap’n! Investing in AI is like buying shares in a whaling voyage captained by a man who knows all about ships and little about whales, https://3quarksdaily.com/3quarksdaily/2023/12/aye-aye-capn-investing-in-ai-is-like-buying-shares-in-a-whaling-voyage-captained-by-a-man-who-knows-all-about-ships-and-little-about-whales.html
More recently, I've taken a look at analogical reasoning, which Geoffrey Hinton seems to think will confer some advantage on AIs because they know so much more than we do. And, yes, there's an obvious and important way in which they DO know so much more than individual humans. But identifying and explicating intellectually fruitful analogies is something else. That's what I explore here: Intelligence, A.I. and analogy: Jaws & Girard, kumquats & MiGs, double-entry bookkeeping & supply and demand, https://new-savanna.blogspot.com/2024/05/intelligence-ai-and-analogy-jaws-girard.html