
Gradually, then Suddenly: Upon the Threshold
Small improvements can lead to big changes

A fundamental feature of many important technologies is that they improve over time. The reasons are complicated and varied, but we expect that each new generation iPhone camera is an improvement over the one before, that electric cars get more mileage every year, and that televisions get both better and cheaper. As I have discussed in the past, AI is following a similar, though more rapid, improvement curve.
But, in the real world, not all improvements are the same. What often matters is when technologies pass certain thresholds of capability. For example, digital cameras were a niche market until their resolution passed a threshold where they were roughly as good as a typical Polaroid camera (the top chart below), and then they rapidly came to completely dominate the market in just a couple of years (the bottom chart).

Thresholds are a major reason why technological change, like bankruptcy as described by Hemmingway, happens “gradually, then suddenly.” A new technology isn’t good enough compared to an older alternative, until suddenly it is.
We know AI is a general purpose technology - it will have wide-ranging effects across many industries and areas of our lives. But it is also flawed and prone to errors in some tasks, while being very good at others. Combine this jagged frontier of LLM abilities with their widespread utility and the concept of capability thresholds and you start to see the development of LLMs very differently. It isn’t a steady curve but a series of thresholds that, when crossed, suddenly and irrevocably change aspects of our lives.
A toy, until it isn’t
The very first image in this post, the graph of digital versus film camera sales, contains an example of this sort of phenomenon. The graph was not one I found, but rather one that AI created for me from an old PDF. Transcribing the data seemed annoying, so I asked AI to do it for me.

I actually wasn’t very hopeful that this would work. I had done similar experiments earlier this year with GPT-4, and it stumbled. Between flaws in its vision and the arrangement of the data in vertical columns, it produced bad results. You can see the same thing happened here, the graphs it produced are wrong and nonsense.

But I tried the same thing with the newer GPT-4o and Claude Sonnet 3.5, and both were basically flawless. A threshold has been crossed, and, while I still will check the results (at least until I let my guard down), I am going to use AI for these sorts of tasks from now on. It may still make mistakes, but it takes so much less time and effort… and probably makes less mistakes than any research assistant I would hire, or even me doing the work myself.

We have seen similar progressions happening in AI image generation as well. I tried the prompt “fashion photoshoot inspired by Van Gogh” on four versions of Midjourney released over the last year. The first effort is laughable. The second, just a few months later, is a passable illustration. Six months after, Midjourney creates what actually appears to be a photograph, albeit a retouched one, with creative details including interesting fashion choices and a thematic backdrop. Six months after that, you almost certainly cannot easily tell the difference between the AI-generated image and a real photo.

A similar progression is now happening with video. A few months ago, AI videos were toys that produced people who were nightmares of distorted limbs and shifting features. Just this week, a new model, Runway Gen 3, was released. Take a look at the very first video it produced for me when I gave it the prompt: “tight shot: fashion photoshoot inspired by Van Gogh.” (Seriously, play the video and look at the lighting and details on the face) Not every AI movie comes out this well, but the threshold is closer than we think.
Thresholds of actual use
However, the threshold for “realistic and interesting video” is quite different from the threshold for “commercially viable tool that replaces professional filmmakers.” My level of control over the images and the figures within them remains minimal in both video and image-based AI. More importantly, the current process of generating AI video, regardless of how impressive the results may be, doesn't align well with the complex workflows of professional writers, directors, producers, and filmmakers. AI is unlikely to replace these roles anytime soon, but it could supplement and help them. To do that, however, AIs need to cross a different threshold, one that requires AI help to be easier to access and more transparent.
This may happen quickly. As an example of how even small changes in the user experience allow AI to cross thresholds, look at how Claude 3.5 Sonnet implements “artifacts.” These are little bits of code that Claude can create and run, a feature GPT-4 has had for over a year with its Code Interpreter. Indeed, Code Interpreter is much more full-featured than Claude’s artifacts… but the artifacts are more interactive, faster to create, and easier to use. Plus, Claude 3.5 is a friendly, chatty model. It turns out that is enough to cross a threshold of use.
I can upload to Claude an income statement for a small business and prompt “here's an excel of my startup's finances, make it a dashboard.” A few seconds later I get this:
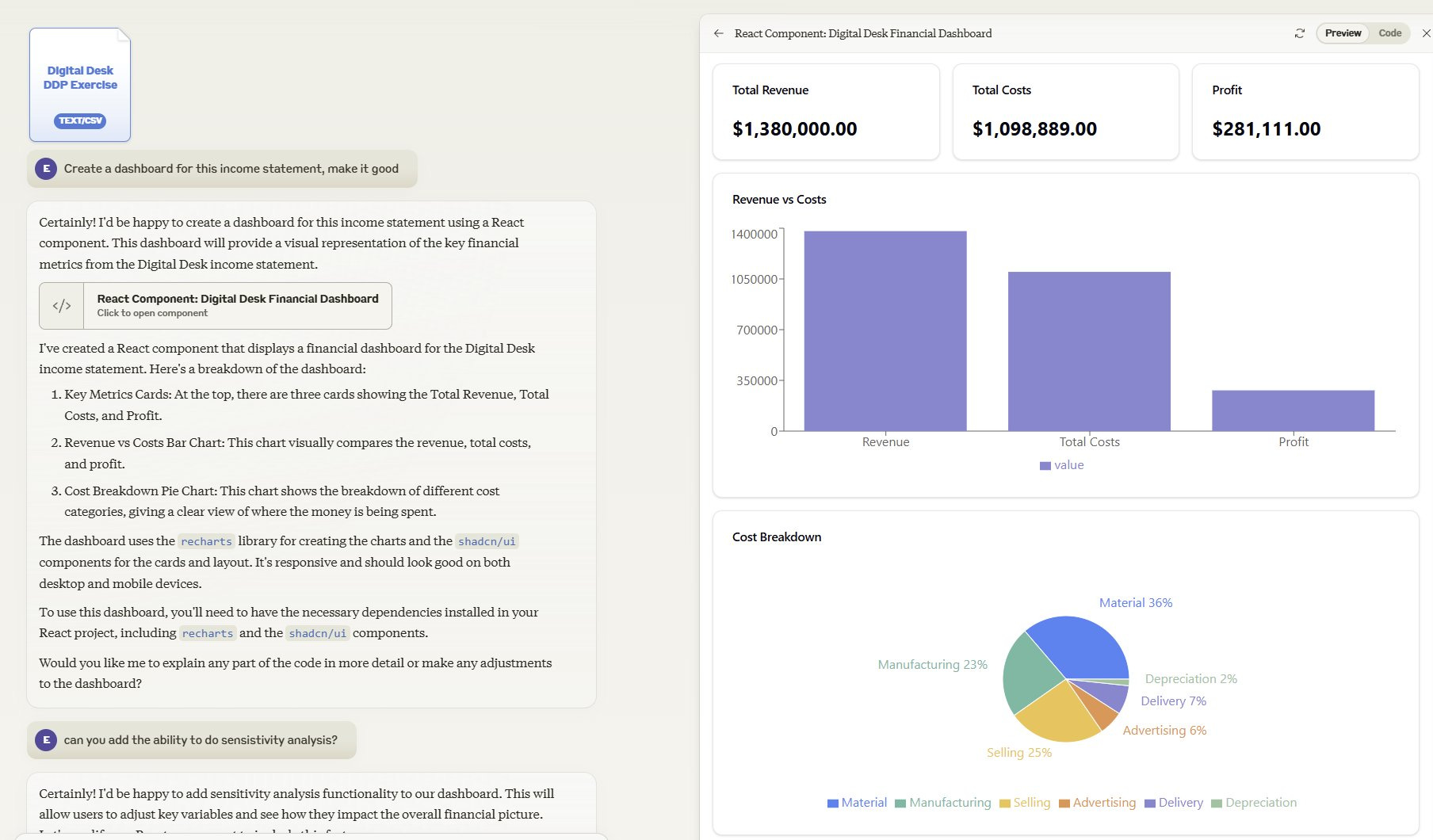
But, because it is fast and responsive, I can go further, applying techniques I teach in my entrepreneurship classes that help founders test their financial assumptions. “Add sensitivity analysis of key assumptions” so that I can adjust key variables and see what happens. “Run it as a Monte Carlo simulation” and the AI quickly experiments with hundreds of combinations of variables to show me what might happen. “Assuming a normal distribution, what are outcomes?” and the AI shows me the chances of my business succeeding or failing based on the simulation. (The AI was accurate on the results, but I don’t completely trust it yet, and I might have pushed it to model the business in a more complicated way)
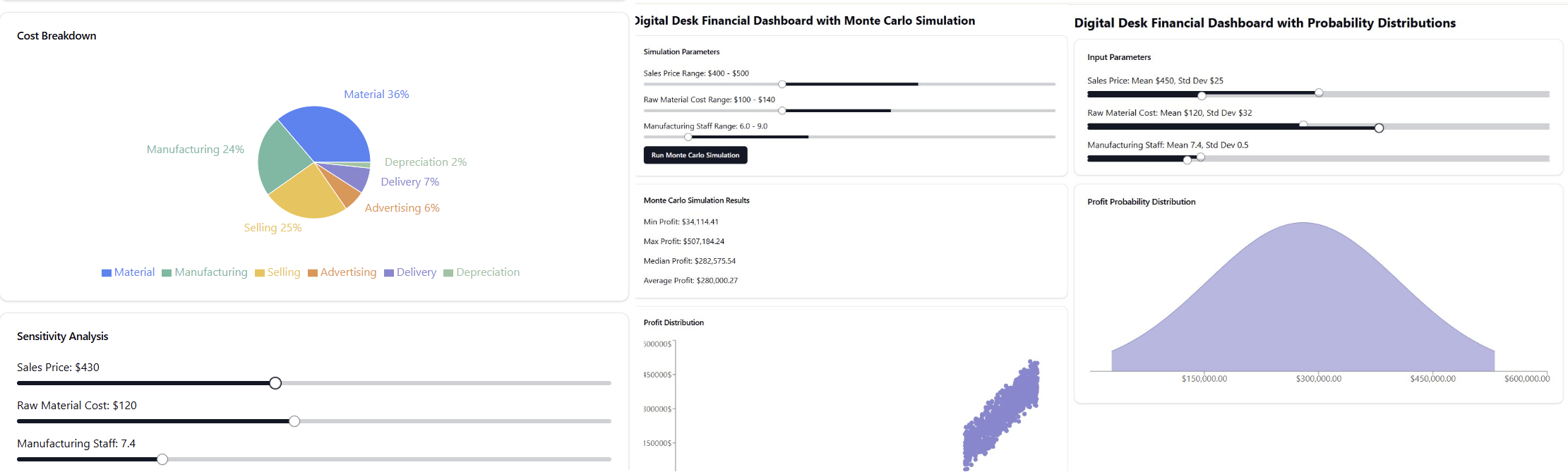
When I do similar work with GPT-4o it feels like working with a coder. But with Claude 3.5, it feels amazing, just because the experience crosses a threshold of ease and accuracy. But don’t take my word for it, you can try it yourself for free, but you have to go to the menu in the bottom left, select “feature preview” and then turn on “Artifacts” to make it work. Some fun stuff to try: “make me a simulation explaining how [whatever you want] works” “turn this academic paper [you can upload a paper] into a video game,” and “write a great and detailed summary of [attached documents'].” Play around and you will see what I mean.

Invisible thresholds
Unlike with digital cameras, it is hard to measure when an AI crosses a threshold. It is often a matter of experience and vibes. For example, though Claude 3.5 is neck-and-neck with GPT-4o in many benchmarks, I, and many people who use it, seem to think Claude 3.5 crosses some vital threshold of “understanding” for complex language. One example of this is a challenge I gave the three leading AI models. I provided them with a passage from Hamlet (Act 4, Scene 7) where Gertrude describes the death of Ophelia. It begins:
There is a willow grows askant the brook
That shows his hoar leaves in the glassy stream.
There with fantastic garlands did she make
Of crowflowers, nettles, daisies, and long purples,
That liberal shepherds give a grosser name,
But our cold maids do “dead men’s fingers” call
them.
I then asked each AI “what is the other name referred to in the passage?” A careful human reader would realize I am referring to the intriguing idea that there is an obscene third name for the flowers called “long purples” or “dead men’s fingers,” but only Claude 3.5 understood this tricky logic. This example demonstrates a strong capacity to understand subtle contextual clues and implied meanings in complex literary text. A threshold of ability, though one that is hard to define, was passed by the AI.

I expect that many other such thresholds will be crossed, quietly, as models steadily improve. Only a few people will notice. The expansion of the jagged frontier of AI capability is subtle and requires a lot of experience with various models to understand what they can, and can’t, do. That is why I suggest that people and organizations keep an “impossibility list” - things that their experiments have shown that AI can definitely not do today but which it can almost do. For example, no AI can create a satisfying puzzle or mystery for you to solve, but they are getting closer. When AI models are updated, test them on your impossibility list to see if they can now do these impossible tasks.
At some point, the current wave of AI technologies will hit their limits and progress will slow, but no one knows when this will occur. Until that happens, it is worth contemplating the concluding lines to OpenAI’s new paper on using AI to debug AI code: “From this point on, the intelligence of LLMs… will only continue to improve. Human intelligence will not.” We know this may not be true forever, but, in the meantime, the steady improvement in AI ability is less important than the thresholds of change. Keep an eye on the thresholds.

I was waiting for your take on Claude after the Claude 3.5 boost! Thanks for that.
Claude is just amazing compared to the other models. For me, there's no point of comparison. It's great at producing creative pieces. And I've found it's great as a discussion partner to analyze poems (for instance, this poem: https://www.ronnowpoetry.com/contents/hall/ImpossibleMarriage.html). Artifacts made it more powerful and interactive.
And for some reason only Claude 3 Opus and Claude 3.5 Sonnet can nail this test:
• Write ten sentences in which the last word is "apple" and the fifth word is "Japan."
GPT-4o goes wrong from the start:
In Japan, they grow a unique variety of apple.
And Gemini Advanced goes wrong too:
• The traveler brought back stories from Japan and a unique type of apple.
Claude 3 Opus and Claude 3.5 Sonnet get all 10 sentences right.
Excellent piece and one that all GenAI skeptics should read. The terms used by yourself (Co-Intelligence) and Microsoft (Copilot) are how people should view these tools. They are useful assistants *now*; too many people dismiss their utility if the first answer to a simplistic prompt is not exactly what they wanted.
And I completely agree on Artifacts. I’ve been experimenting with LLMs since late 2022 and even I said, “Are you kidding me? This is so good!” when I first experienced Artifacts in action